Chapter 2 크롤링을 위한 기본 지식
프로그래밍에 익숙한 분들도 크롤링은 생소한 경우가 많습니다. 기본적인 프로그래밍에 관한 책과 강의가 굉장히 많지만 크롤링을 다루는 자료는 접하기 힘들기 때문입니다. 크롤링은 기계적인 단계가 많기 때문에 조금만 연습해도 활용할 수 있는 기술입니다. 그러나 복잡한 웹페이지나 데이터 내용을 수집하려면 인코딩, 통신 구조에 대한 지식이 필요할 때가 있습니다.
이 CHAPTER에서는 크롤링을 하기 위해 사전에 알고 있으면 도움이 되는 인코딩, 웹의 동작 방식, HTML과 CSS에 대해 알아보겠습니다. 그리고 실제 크롤링 시 유용한 파이프 오퍼레이터와 오류에 대한 예외처리도 알아보겠습니다.
2.1 인코딩의 이해와 R에서 UTF-8 설정하기
2.1.1 인간과 컴퓨터 간 번역의 시작, ASCII
R에서 스크립트를 한글로 작성해 저장한 후 이를 다시 불러올 때, 혹은 한글로 된 데이터를 크롤링하면 오류가 뜨거나 읽을 수 없는 문자로 나타나는 경우가 종종 있습니다. 이는 한글 인코딩 때문에 발생하는 문제이며, 이러한 현상을 흔히 ‘인코딩이 깨졌다’라고 표현합니다. 인코딩이란 사람이 사용하는 언어를 컴퓨터가 사용하는 0과 1로 변환하는 과정을 말하며, 이와 반대의 과정을 디코딩이라고 합니다.
이렇듯 사람과 컴퓨터 간의 언어를 번역하기 위해 최초로 사용된 방식이 아스키(ASCII: American Standard Code for Information Interchange)입니다. 0부터 127까지 총 128개 바이트에 알파벳과 숫자, 자주 사용되는 특수문자 값을 부여하고, 문자가 입력되면 이에 대응되는 바이트가 저장됩니다. 그러나 아스키의 ‘American’이라는 이름에서 알 수 있듯이 이는 영어의 알파벳이 아닌 다른 문자를 표현하는 데 한계가 있으며, 이를 보완하기 위한 여러 방법이 나오게 되었습니다.
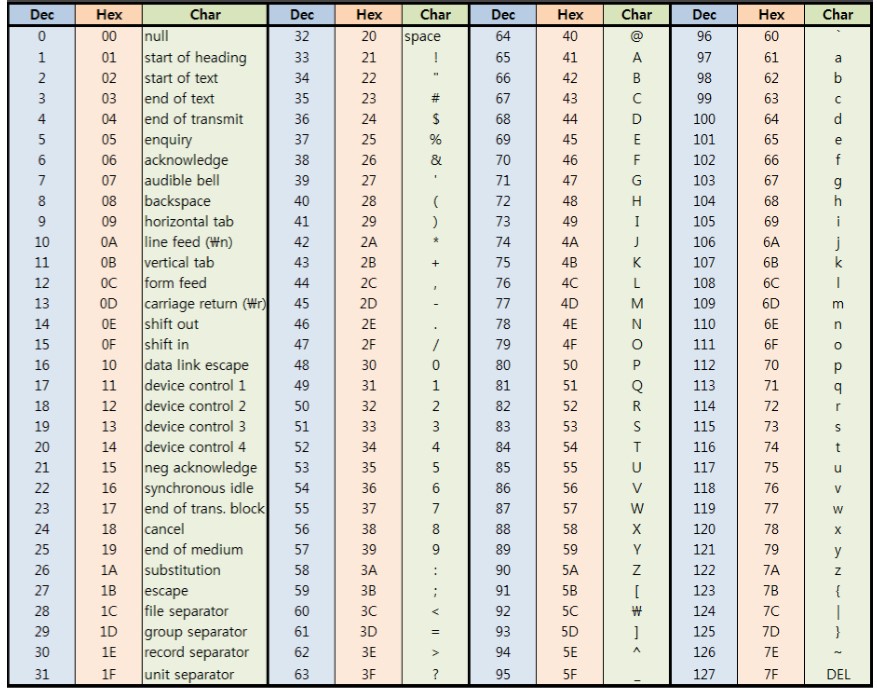
그림 2.1: 아스키 코드 표
2.1.2 한글 인코딩 방식의 종류
인코딩에 대한 전문적인 내용은 이 책의 범위를 넘어가며, 크롤링을 위해서는 한글을 인코딩하는 데 쓰이는 EUC-KR과 CP949, UTF-8 정도만 이해해도 충분합니다. 만일 ‘알’이라는 단어를 인코딩한다면 어떤 방법이 있을까요? 먼저 ‘알’이라는 문자 자체에 해당하는 코드를 부여해 나타내는 방법이 있습니다. 아니면 이를 구성하는 모음과 자음을 나누어 ㅇ, ㅏ, ㄹ 각각에 해당하는 코드를 부여하고 이를 조합할 수도 있습니다. 전자와 같이 완성된 문자 자체로 나타내는 방법을 완성형, 후자와 같이 각 자모로 나타내는 방법을 조합형이라고 합니다.
한글 인코딩 중 완성형으로 가장 대표적인 방법은 EUC-KR입니다. EUC-KR은 현대 한글에서 많이 쓰이는 문자 2,350개에 번호를 붙인 방법입니다. 그러나 2,350개 문자로 모든 한글 자모의 조합을 표현하기 부족해, 이를 보완하고자 마이크로소프트가 도입한 방법이 CP949입니다. CP949는 11,720개 한글 문자에 번호를 붙인 방법으로 기존 EUC-KR보다 나타낼 수 있는 한글의 개수가 훨씬 많아졌습니다. 윈도우의 경우 기본 인코딩이 CP949로 되어 있습니다.
조합형의 대표적 방법인 UTF-8은 모음과 자음 각각에 코드를 부여한 후 조합해 한글을 나타냅니다. 조합형은 한글뿐만 아니라 다양한 언어에 적용할 수 있다는 장점이 있어 전 세계 웹페이지의 대부분이 UTF-8로 만들어지고 있습니다.
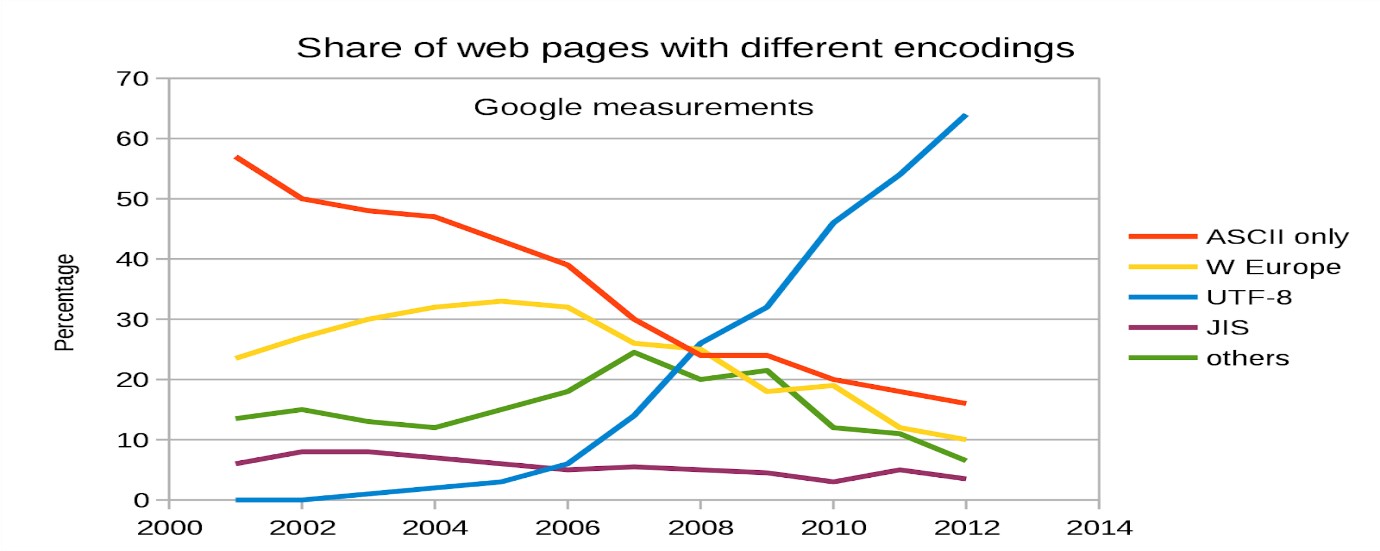
그림 2.2: 웹페이지에서 사용되는 인코딩 비율
2.1.3 R에서 UTF-8 설정하기
윈도우에서는 기본 인코딩이 CP949로 이루어져 있으며, 일부 국내 웹사이트는 EUC-KR로 인코딩이 된 경우도 있습니다. 반면 R의 여러 함수는 인코딩이 UTF-8로 이루어져 있어, 인코딩 방식의 차이로 인해 스크립트 작성 및 크롤링 과정에서 오류가 발생하는 경우가 종종 있습니다.
만일 CP949 인코딩을 그대로 사용하면 미리 저장되었던 한글 스크립트가 깨져 나오는 일이 발생할 수 있습니다. 이를 방지하기 위해 그림 2.3과 같이 기본 인코딩을 UTF-8로 변경해주는 것이 좋습니다. R Studio의 [Tools → Global Options] 메뉴에서 [Code → Saving] 항목 중 [Default text encodings] 항목을 통해 기본 인코딩을 UTF-8로 변경합니다.
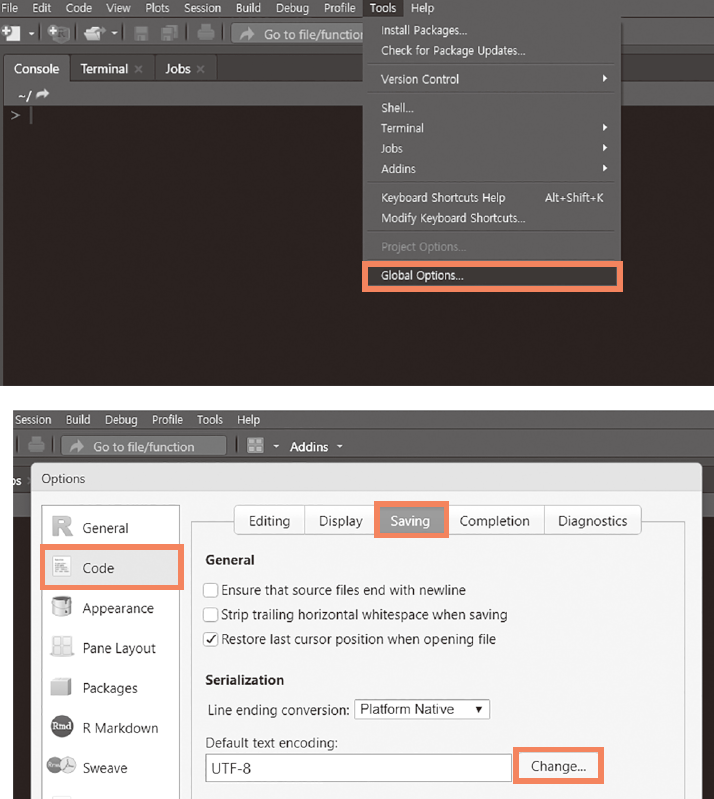
그림 2.3: 인코딩 변경
해당 방법으로도 해결되지 않는다면 그림 2.4와 같이 [File → Reopen with Encoding] 메뉴에서 [UTF-8] 항목을 선택하고 [Set as default encoding for source files] 항목을 선택한 후 [OK]를 클릭합니다. UTF-8로 인코딩이 설정된 후 파일을 다시 엽니다.
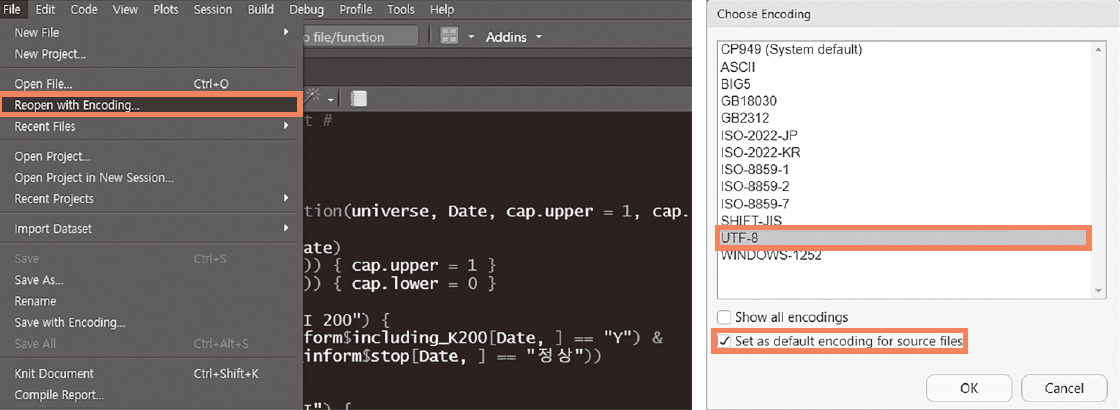
그림 2.4: 인코딩 변경 후 재시작
2.2 웹의 동작 방식
크롤링은 웹사이트의 정보를 수집하는 과정입니다. 따라서 웹이 어떻게 동작하는지 이해할 필요가 있습니다.
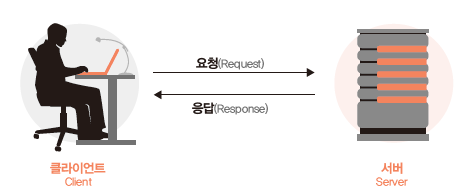
그림 2.5: 웹 환경 구조
먼저 클라이언트란 여러분의 데스크톱이나 휴대폰과 같은 장치와 크롬이나 파이어폭스와 같은 소프트웨어를 의미합니다. 서버는 웹사이트와 앱을 저장하는 컴퓨터를 의미합니다. 클라이언트가 특정 정보를 요구하는 과정을 ‘요청’이라고 하며, 서버가 해당 정보를 제공하는 과정을 ‘응답’이라고 합니다. 그러나 클라이언트와 서버가 연결되어 있지 않다면 둘 사이에 정보를 주고받을 수 없으며, 이를 연결하는 공간이 바로 인터넷입니다. 또한 건물에도 고유의 주소가 있는 것처럼, 각 서버에도 고유의 주소가 있는데 이것이 인터넷 주소 혹은 URL입니다.
여러분이 네이버에서 경제 기사를 클릭하는 경우를 생각해봅시다. 클라이언트는 사용자인 여러분이고, 서버는 네이버이며, URL은 www.naver.com이 됩니다. 경제 기사를 클릭하는 과정이 요청이며, 클릭 후 해당 페이지를 보여주는 과정이 응답입니다.
2.2.1 HTTP
클라이언트가 각기 다른 방법으로 데이터를 요청한다면, 서버는 해당 요청을 알아듣지 못할 것입니다. 이를 방지하기 위해 규정된 약속이나 표준에 맞추어 데이터를 요청해야 합니다. 이러한 약속을 HTTP(HyperText Transfer Protocol)라고 합니다.
클라이언트가 서버에게 요청의 목적이나 종류를 알리는 방법을 HTTP 요청 방식(HTTP Request Method)이라고 합니다. HTTP 요청 방식은 크게 표 2.1와 같이 GET, POST, PUT, DELETE라는 네 가지로 나눌 수 있지만 크롤링에는 GET과 POST 방식이 대부분 사용되므로 이 두 가지만 알아도 충분합니다. GET 방식과 POST 방식의 차이 및 크롤링 방법은 CHAPTER 4에서 자세하게 다루겠습니다.
| 요청방식 | 주소 |
|---|---|
| GET | 특정 정보 조회 |
| POST | 새로운 정보 등록 |
| PUT | 기존 특정 정보 갱신 |
| DELETE | 기존 특정 정보 삭제 |
인터넷을 사용하다 보면 한 번쯤 ‘이 페이지를 볼 수 있는 권한이 없음(HTTP 오류 403 - 사용할 수 없음)’ 혹은 ‘페이지를 찾을 수 없음(HTTP 오류 404 - 파일을 찾을 수 없음)’이라는 오류를 본 적이 있을 겁니다. 여기서 403과 404라는 숫자는 클라이언트의 요청에 대한 서버의 응답 상태를 나타내는 HTTP 상태 코드입니다.
HTTP 상태 코드는 100번대부터 500번대까지 있으며, 성공적으로 응답을 받을 시 200번 코드를 받게 됩니다. 각 코드에 대한 내용은 HTTP 상태 코드를 검색하면 확인할 수 있으며, 크롤링 과정에서 오류가 발생할 시 해당 코드를 통해 어떤 부분에서 오류가 발생했는지 확인이 가능합니다.
| 코드 | 주소 | 내용 |
|---|---|---|
| 1xx | Informational (조건부 응답) | 리퀘스트를 받고, 처리 중에 있음 |
| 2xx | Success (성공) | 리퀘스트를 정상적으로 처리함 |
| 3xx | Redirection (리디렉션) | 리퀘스트 완료를 위해 추가 동작이 필요함 |
| 4xx | Client Error (클라이언트 오류) | 클라이언트 요청을 처리할 수 없어 오류 발생 |
| 5xx | Server Error (서버 오류) | 서버에서 처리를 하지 못하여 오류 발생 |
2.3 HTML과 CSS
클라이언트와 서버가 데이터를 주고받을 때는 디자인이라는 개념이 필요하지 않습니다. 그러나 응답받은 정보를 사람이 확인하려면 보기 편한 방식으로 바꾸어줄 필요가 있는데 웹페이지가 그러한 역할을 합니다. 웹페이지의 제목, 단락, 목록 등 레이아웃을 잡아주는 데 쓰이는 대표적인 마크업 언어가 HTML(HyperText Markup Language)입니다. HTML을 통해 잡혀진 뼈대에 글자의 색상이나 폰트, 배경색, 배치 등 화면을 꾸며주는 역할을 하는 것이 CSS(Cascading Style Sheets)입니다.
우리의 목적은 웹페이지를 만드는 것이 아니므로 HTML과 CSS에 대해 자세히 알 필요는 없습니다. 그러나 크롤링하고자 하는 데이터가 웹페이지의 어떤 태그 내에 위치하고 있는지, 어떻게 크롤링하면 될지 파악하기 위해서는 HTML과 CSS에 대한 기본적인 지식은 알아야 합니다.
메모장에서 HTML 코드를 입력한 후 ‘파일명.html’로 저장하면 해당 코드가 웹페이지에서 어떻게 나타나는지 확인할 수 있습니다.
2.3.1 HTML 기본 구조
HTML은 크게 메타 데이터를 나타내는 head와 본문을 나타내는 body로 나누어집니다. head에서 title은 웹페이지에서 나타나는 제목을 나타내며 body 내에는 본문에 들어갈 각종 내용들이 포함되어 있습니다.
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h2> This is page heading </h2>
<p> THis is first paragraph text </p>
</body>
</html>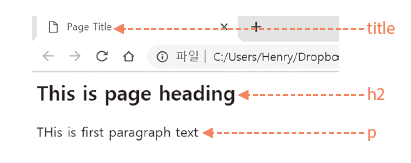
그림 2.6: HTML 기본 구조
2.3.2 태그와 속성
HTML 코드는 태그와 속성, 내용으로 이루어져 있습니다. 크롤링한 데이터에서 특정 태그의 데이터만을 찾는 방법, 특정 속성의 데이터만을 찾는 방법, 뽑은 자료에서 내용만을 찾는 방법 등 내용을 찾는 방법이 모두 다르기 때문에 태그와 속성에 대해 좀 더 자세히 살펴보겠습니다.
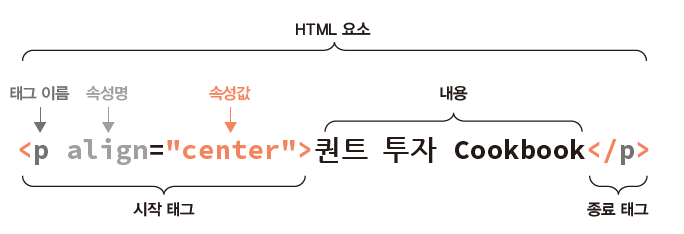
그림 2.7: HTML 구성 요소 분석
꺾쇠(<>)로 감싸져 있는 부분을 태그라고 하며, 여는 태그 <>가 있으면 반드시 이를 닫는 태그인 </>가 쌍으로 있어야 합니다. 속성은 해당 태그에 대한 추가적인 정보를 제공해주는 것으로, 뒤에 속성값이 따라와야 합니다. 내용은 우리가 눈으로 보는 텍스트 부분을 의미합니다. 앞의 HTML 코드는 문단을 나타내는 <p>, 정렬을 나타내는 align 속성과 center를 통해 가운데 정렬을 지정하며, 내용에는 ‘퀀트 투자 Cookbook’을 나타내고, </p> 태그를 통해 태그를 마쳤습니다.
2.3.3 h 태그와 p 태그
h 태그는 폰트의 크기를 나타내는 태그이며, p 태그는 문단을 나타내는 태그입니다. 이를 사용한 간단한 예제는 다음과 같습니다. h 태그의 숫자가 작을수록 텍스트 크기는 커지는 것이 확인되며, 숫자는 1에서 6까지 지원됩니다. p 태그를 사용하면 각각의 문단이 만들어지는 것이 확인됩니다.
<html>
<body>
<h1>Page heading: size 1</h1>
<h2>Page heading: size 2</h2>
<h3>Page heading: size 3</h3>
<p>Quant Cookbook</p>
<p>By Henry</p>
</body>
</html>
그림 2.8: h 태그와 p 태그 예제
2.3.4 리스트를 나타내는 ul 태그와 ol 태그
ul과 ol 태그는 리스트(글머리 기호)를 만들 때 사용됩니다. ul은 순서가 없는 리스트(unordered list), ol은 순서가 있는 리스트(ordered list)를 만듭니다.
<html>
<body>
<h2> Unordered List</h2>
<ul>
<li>Price</li>
<li>Financial Statement</li>
<li>Sentiment</li>
</ul>
<h2> Ordered List</h2>
<ol>
<li>Import</li>
<li>Tidy</li>
<li>Understand</li>
<li>Communicate</li>
</ol>
</body>
</html>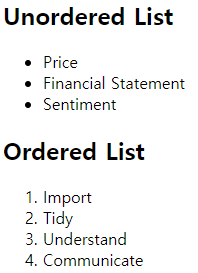
그림 2.9: 리스트 관련 태그 예제
ul 태그로 감싼 부분은 글머리 기호가 순서가 없는 •으로 표현되며, ol 태그로 감싼 부분은 숫자가 순서대로 표현됩니다. 각각의 리스트는 li를 통해 생성됩니다.
2.3.5 table 태그
table 태그는 표를 만드는 태그입니다.
<html>
<body>
<h2>Major Stock Indices and US ETF</h2>
<table>
<tr>
<th>Country</th>
<th>Index</th>
<th>ETF</th>
</tr>
<tr>
<td>US</td>
<td>S&P 500</td>
<td>IVV</td>
</tr>
<tr>
<td>Europe</td>
<td>Euro Stoxx 50</td>
<td>IEV</td>
</tr>
<tr>
<td>Japan</td>
<td>Nikkei 225</td>
<td>EWJ</td>
</tr>
<tr>
<td>Korea</td>
<td>KOSPI 200</td>
<td>EWY</td>
</tr>
</table>
</body>
</html>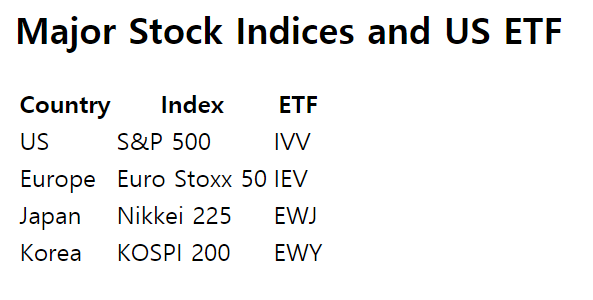
그림 2.10: table 태그 예제
table 태그 내의 tr 태그는 각 행을 의미합니다. 각 셀의 구분은 th 혹은 td 태그를 통해 구분할 수 있습니다. th 태그는 진하게 표현되므로 주로 테이블의 제목에 사용되고, td 태그는 테이블의 내용에 사용됩니다.
2.3.6 a 태그와 img 태그 및 속성
a 태그와 img 태그는 다른 태그와는 다르게, 혼자 쓰이기보다는 속성과 결합해 사용됩니다. a 태그는 href 속성과 결합해 다른 페이지의 링크를 걸 수 있습니다. img 태그는 src 속성과 결합해 이미지를 불러옵니다.
<html>
<body>
<h2>a tag & href attribute</h2>
<p>HTML links are defined with the a tag.
The link address is specified in the href attribute:</p>
<a href="https://henryquant.blogspot.com/">Henry's Quantopia</a>
<h2>img tag & src attribute</h2>
<p>HTML images are defined with the img tag,
and the filename of the image source is
specified in the src attribute:</p>
<img src="https://cran.r-project.org/Rlogo.svg",
width="180",height="140">
</body>
</html>
그림 2.11: a 태그와 src 태그 예제
a 태그 뒤 href 속성의 속성값으로 연결하려는 웹페이지 주소를 입력한 후 내용을 입력하면, 내용 텍스트에 웹페이지의 링크가 추가됩니다. img 태그 뒤 src 속성의 속성값에는 불러오려는 이미지 주소를 입력하며, width 속성과 height 속성을 통해 이미지의 가로세로 길이를 조절할 수도 있습니다. 페이지 내에서 링크된 주소를 모두 찾거나, 모든 이미지를 저장하려고 할 때 속성값을 찾으면 손쉽게 원하는 작업을 할 수 있습니다.
2.3.7 div 태그
div 태그는 화면의 전체적인 틀(레이아웃)을 만들 때 주로 사용하는 태그입니다. 단독으로도 사용될 수 있으며, 꾸밈을 담당하는 style 속성과 결합되어 사용되기도 합니다.
<html>
<body>
<div style="background-color:black;color:white">
<h5>First Div</h5>
<p>Black backgrond, White Color</p>
</div>
<div style="background-color:yellow;color:red">
<h5>Second Div</h5>
<p>Yellow backgrond, Red Color</p>
</div>
<div style="background-color:blue;color:grey">
<h5>Second Div</h5>
<p>Blue backgrond, Grey Color</p>
</div>
</body>
</html>
그림 2.12: div 태그 예제
div 태그를 통해 총 세 개의 레이아웃으로 나누어진 것을 알 수 있습니다. style 속성 중 background-color는 배경 색상을, color는 글자 색상을 의미하며, 각 레이아웃마다 다른 스타일이 적용되었습니다.
2.3.8 CSS
CSS는 앞서 설명했듯이 웹페이지를 꾸며주는 역할을 합니다. head에서 각 태그에 CSS 효과를 입력하면 본문의 모든 해당 태그에 CSS 효과가 적용됩니다. 이처럼 웹페이지를 꾸미기 위해 특정 요소에 접근하는 것을 셀렉터(Selector)라고 합니다.
<html>
<head>
<style>
body {background-color: powderblue;}
h4 {color: blue;}
</style>
</head>
<body>
<h4>This is a heading</h4>
<p>This is a first paragraph.</p>
<p>This is a second paragraph.</p>
</body>
</html>
그림 2.13: css 예제
head 태그 사이에 여러 태그에 대한 CSS 효과가 정의되었습니다. 먼저 body의 전체 배경 색상을 powderblue로 설정했으며, h4 태그의 글자 색상은 파란색(blue)으로 설정했습니다. body 태그 내에서 style에 태그를 주지 않더라도, CSS 효과가 모두 적용되었음이 확인됩니다.
2.3.9 클래스와 id
CSS를 이용하면 본문의 모든 태그에 효과가 적용되므로, 특정한 요소(Element)에만 동일한 효과를 적용할 수 없습니다. 클래스 속성을 이용하면 동일한 이름을 가진 클래스에는 동일한 효과가 적용됩니다.
<html>
<style>
.index {
background-color: tomato;
color: white;
padding: 10px;
}
.desc {
background-color: moccasin;
color: black;
padding: 10px;
}
</style>
<div>
<h2 class="index">S&P 500</h2>
<p class="desc"> Market capitalizations of 500 large companies
having common stock listed on the NYSE, NASDAQ,
or the Cboe BZX Exchange</p>
</div>
<div>
<h2>Dow Jones Industrial Average</h2>
<p>Value of 30 large, publicly owned companies
based in the United States</p>
</div>
<div>
<h2 class="index">NASDAQ Composite</h2>
<p class="desc">The composition of the NASDAQ Composite is
heavily weighted towards information technology companies</p>
<div>
</html>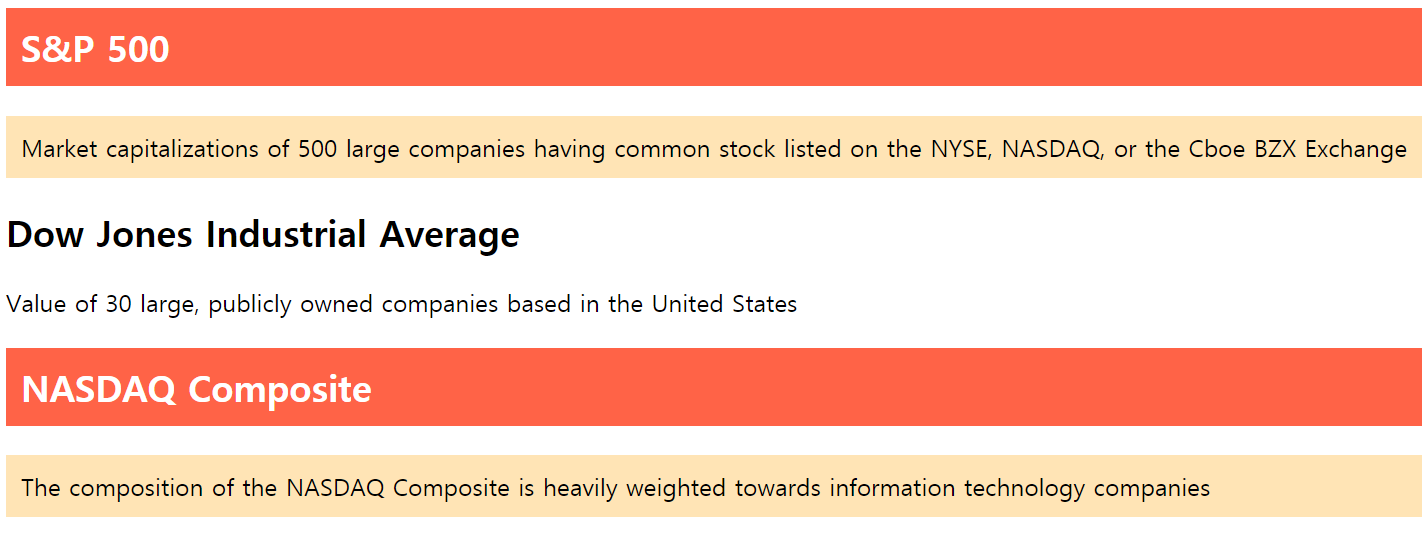
그림 2.14: class 예제
셀렉터를 클래스에 적용할 때는 클래스명 앞에 마침표(.)를 붙여 표현합니다. 위 예제에서 index 클래스는 배경 색상이 tomato, 글자 색상은 흰색, 여백은 10px로 정의되었습니다. desc 클래스는 배경 색상이 moccasin, 글자 색상은 검은색, 여백은 10px로 정의되었습니다. 본문의 첫 번째(S&P 500)와 세 번째(NASDAQ Composite) 레이아웃의 h2 태그 뒤에는 index 클래스를, p 태그 뒤에는 desc 클래스를 속성으로 입력했습니다. 따라서 해당 레이아웃에만 CSS 효과가 적용되며, 클래스 값이 없는 두 번째 레이아웃에는 효과가 적용되지 않습니다.
id 또한 이와 비슷한 역할을 하며, HTML 내에서 여러 개의 클래스가 정의될 수 있는 반면, id는 단 하나만 사용하기를 권장합니다.
<html>
<head>
<style>
/* Style the element with the id "myHeader" */
#myHeader {
background-color: lightblue;
color: black;
padding: 15px;
text-align: center;
}
</style>
</head>
<body>
<!-- A unique element -->
<h1 id="myHeader">My Header</h1>
</body>
</html>
그림 2.15: id 예제
셀렉터를 id에 적용할 때는 클래스명 앞에 샵(#)를 붙여 표현하며, 페이지에서 한 번만 사용된다는 점을 제외하면 클래스와 사용 방법이 거의 동일합니다. 클래스나 id 값을 통해 원하는 내용을 크롤링하는 경우도 많으므로, 각각의 이름 앞에 마침표(.)와 샵(#) 을 붙여야 한다는 점을 꼭 기억하기 바랍니다.
HTML과 관련해 추가적인 정보가 필요하거나 내용이 궁금하다면 아래 웹사이트를 참고하기 바랍니다.
- w3schools: https://www.w3schools.in/html-tutorial/
- 웨버 스터디: http://webberstudy.com/
2.4 파이프 오퍼레이터(%>%)
파이프 오퍼레이터는 R에서 동일한 데이터를 대상으로 연속으로 작업하게 해주는 오퍼레이터(연산자)입니다. 크롤링에 필수적인 rvest 패키지를 설치하면 자동으로 magrittr 패키지가 설치되어 파이프 오퍼레이터를 사용할 수 있습니다.
흔히 프로그래밍에서 x라는 데이터를 F()라는 함수에 넣어 결괏값을 확인하고 싶으면 F(x)의 방법을 사용합니다. 예를 들어 3과 5라는 데이터 중 큰 값을 찾으려면 max(3,5)를 통해 확인합니다. 이를 통해 나온 결괏값을 또 다시 G()라는 함수에 넣어 결괏값을 확인하려면 비슷한 과정을 거칩니다. max(3,5)를 통해 나온 값의 제곱근을 구하려면 result = max(3,5)를 통해 첫 번째 결괏값을 저장하고, sqrt(result)를 통해 두 번째 결괏값을 계산합니다. 물론 sqrt(max(3,5))와 같은 표현법으로 한 번에 표현할 수 있습니다.
이러한 표현의 단점은 계산하는 함수가 많아질수록 저장하는 변수가 늘어나거나 괄호가 지나치게 길어진다는 것입니다. 그러나 파이프 오퍼레이터인 %>%를 사용하면 함수 간의 관계를 매우 직관적으로 표현하고 이해할 수 있습니다. 이를 정리하면 아래 표 2.3와 같습니다.
| 내용 | 표현.방법 |
|---|---|
| F(x) | x %>% F |
| G(F(x)) | x %>% F %>% G |
간단한 예제를 통해 파이프 오퍼레이터의 사용법을 살펴보겠습니다. 먼저 다음과 같은 10개의 숫자가 있다고 가정합니다.
x = c(0.3078, 0.2577, 0.5523, 0.0564, 0.4685,
0.4838, 0.8124, 0.3703, 0.5466, 0.1703)우리가 원하는 과정은 다음과 같습니다.
- 각 값들의 로그값을 구할 것
- 로그값들의 계차를 구할 것
- 구해진 계차의 지수값을 구할 것
- 소수 둘째 자리까지 반올림할 것
입니다. 즉 log(), diff(), exp(), round()에 대한 값을 순차적으로 구하고자 합니다.
x1 = log(x)
x2 = diff(x1)
x3 = exp(x2)
round(x3, 2)## [1] 0.84 2.14 0.10 8.31 1.03 1.68 0.46 1.48 0.31첫 번째 방법은 단계별 함수의 결괏값을 변수에 저장하고 저장된 변수를 다시 불러와 함수에 넣고 계산하는 방법입니다. 전반적인 계산 과정을 확인하기에는 좋지만 매번 변수에 저장하고 불러오는 과정이 매우 비효율적이며 코드도 불필요하게 길어집니다.
round(exp(diff(log(x))), 2)## [1] 0.84 2.14 0.10 8.31 1.03 1.68 0.46 1.48 0.31두 번째는 괄호를 통해 감싸는 방법입니다. 앞선 방법에 비해 코드는 짧아졌지만, 계산 과정을 알아보기에는 매우 불편한 방법으로 코드가 짜여 있습니다.
library(magrittr)
x %>% log() %>% diff() %>% exp() %>% round(., 2)## [1] 0.84 2.14 0.10 8.31 1.03 1.68 0.46 1.48 0.31마지막으로 파이프 오퍼레이터를 사용하는 방법입니다. 코드도 짧으며 계산 과정을 한눈에 파악하기도 좋습니다. 맨 왼쪽에는 원하는 변수를 입력하며, %>% 뒤에는 차례대로 계산하고자 하는 함수를 입력합니다. 변수의 입력값을 ()로 비워둘 경우, 오퍼레이터의 왼쪽에 있는 값이 입력 변수가 됩니다. 반면 round()와 같이 입력값이 두 개 이상 필요하면 마침표(.)가 오퍼레이터의 왼쪽 값으로 입력됩니다.
파이프 오퍼레이터는 크롤링뿐만 아니라 모든 코드에 사용할 수 있습니다. 이를 통해 훨씬 깔끔하면서도 데이터 처리 과정을 직관적으로 이해할 수 있습니다.
2.5 오류에 대한 예외처리
크롤링을 이용해 데이터를 수집할 때 일반적으로 for loop 구문을 통해 수천 종목에 해당하는 웹페이지에 접속해 해당 데이터를 읽어옵니다. 그러나 특정 종목에 해당하는 페이지가 없거나, 단기적으로 접속이 불안정할 경우 오류가 발생해 루프를 처음부터 다시 실행해야 하는 번거로움이 있습니다. tryCatch() 함수를 이용하면 예외처리, 즉 오류가 발생할 경우 이를 무시하고 넘어갈 수 있습니다.
tryCatch() 함수의 구조는 다음과 같습니다.
result = tryCatch({
expr
}, warning = function(w) {
warning-handler-code
}, error = function(e) {
error-handler-code
}, finally = {
cleanup-code
})먼저 expr는 실행하고자 하는 코드를 의미합니다. warning은 경고를 나타내며, warning-handler-code는 경고 발생 시 실행할 구문을 의미합니다. 이와 비슷하게 error와 error-handler-code는 각각 오류와 오류 발생 시 실행할 구문을 의미합니다. finally는 오류의 여부와 관계 없이 무조건 수행할 구문을 의미하며, 생략할 수도 있습니다.
number = data.frame(1,2,3,"4",5, stringsAsFactors = FALSE)
str(number)## 'data.frame': 1 obs. of 5 variables:
## $ X1 : num 1
## $ X2 : num 2
## $ X3 : num 3
## $ X.4.: chr "4"
## $ X5 : num 5먼저 number 변수에는 1에서 5까지 값이 입력되어 있으며, 다른 값들은 형태가 숫자인 반면 4는 문자 형태입니다.
for (i in number) {
print(i^2)
}## [1] 1
## [1] 4
## [1] 9## Error in i^2: 이항연산자에 수치가 아닌 인수입니다for loop 구문을 통해 순서대로 값들의 제곱을 출력하는 명령어를 실행하면 문자 4는 제곱을 할 수 없어 오류가 발생하게 됩니다. tryCatch() 함수를 사용하면 이처럼 오류가 발생하는 루프를 무시하고 다음 루프로 넘어갈 수 있게 됩니다.
for (i in number) {
tryCatch({
print(i^2)
}, error = function(e) {
print(paste('Error:', i))
})
}## [1] 1
## [1] 4
## [1] 9
## [1] "Error: 4"
## [1] 25expr 부분은 print(i^2)이며, error-handler-code 부분은 오류가 발생한 i를 출력합니다. 해당 코드를 실행하면 문자 4에서 오류가 발생함을 알려준 후 루프가 멈추지 않고 다음으로 진행됩니다.