Chapter 5 금융 데이터 수집하기 (기본)
API와 크롤링을 이용한다면 비용을 지불하지 않고 얼마든지 금융 데이터를 수집할 수있습니다. 이 CHAPTER에서는 금융 데이터를 받기 위해 필요한 주식티커를 구하는 방법과 섹터별 구성종목을 크롤링하는 방법을 알아보겠습니다.
5.1 한국거래소의 산업별 현황 및 개별지표 크롤링
앞 CHAPTER의 예제를 통해 네이버 금융에서 주식티커를 크롤링하는 방법을 살펴보았습니다. 그러나 이 방법은 지나치게 복잡하고 시간이 오래 걸립니다. 반면 한국거래소에서 제공하는 업종분류 현황과 개별종목 지표 데이터를 이용하면 훨씬 간단하게 주식티커 데이터를 수집할 수 있습니다.
- KRX 정보데이터시스템 http://data.krx.co.kr/ 에서 [기본통계 → 주식 → 세부안내] 부분
- [12025] 업종분류 현황
- [12021] 개별종목
해당 데이터들을 크롤링이 아닌 [Excel] 버튼을 클릭해 엑셀 파일로 받을 수도 있습니다. 그러나 매번 엑셀 파일을 다운로드하고 이를 R로 불러오는 작업은 상당히 비효율적이며, 크롤링을 이용한다면 해당 데이터를 R로 직접 불러올 수 있습니다.
5.1.1 업종분류 현황 크롤링
먼저 업종분류 현황에 해당하는 페이지에 접속한 후 개발자 도구 화면을 열고 [다운로드] 버튼을 클릭한 후 [CSV]를 누릅니다. [Network] 탭에는 generate.cmd와 download.cmd 두 가지 항목이 있습니다. 거래소에서 엑셀 데이터를 받는 과정은 다음과 같습니다.
http://data.krx.co.kr/comm/fileDn/download_excel/download.cmd 에 원하는 항목을 쿼리로 발송하면 해당 쿼리에 해당하는 OTP(generate.cmd)를 받게 됩니다.
부여받은 OTP를 http://data.krx.co.kr/에 제출하면 이에 해당하는 데이터(download.cmd)를 다운로드하게 됩니다.
먼저 1번 단계를 살펴보겠습니다.
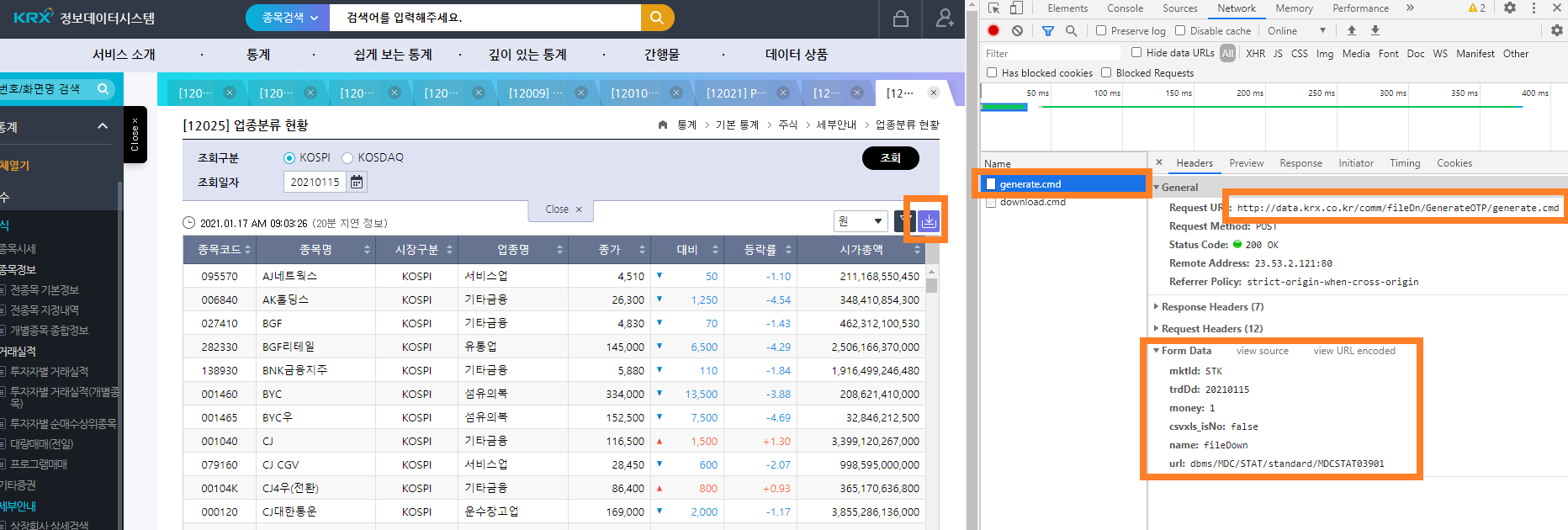
그림 5.1: OTP 생성 부분
General 항목의 Request URL의 앞부분이 원하는 항목을 제출할 주소입니다. Form Data에는 우리가 원하는 항목들이 적혀 있습니다. 이를 통해 POST 방식으로 데이터를 요청함을 알 수 있습니다.
다음으로 2번 단계를 살펴보겠습니다.
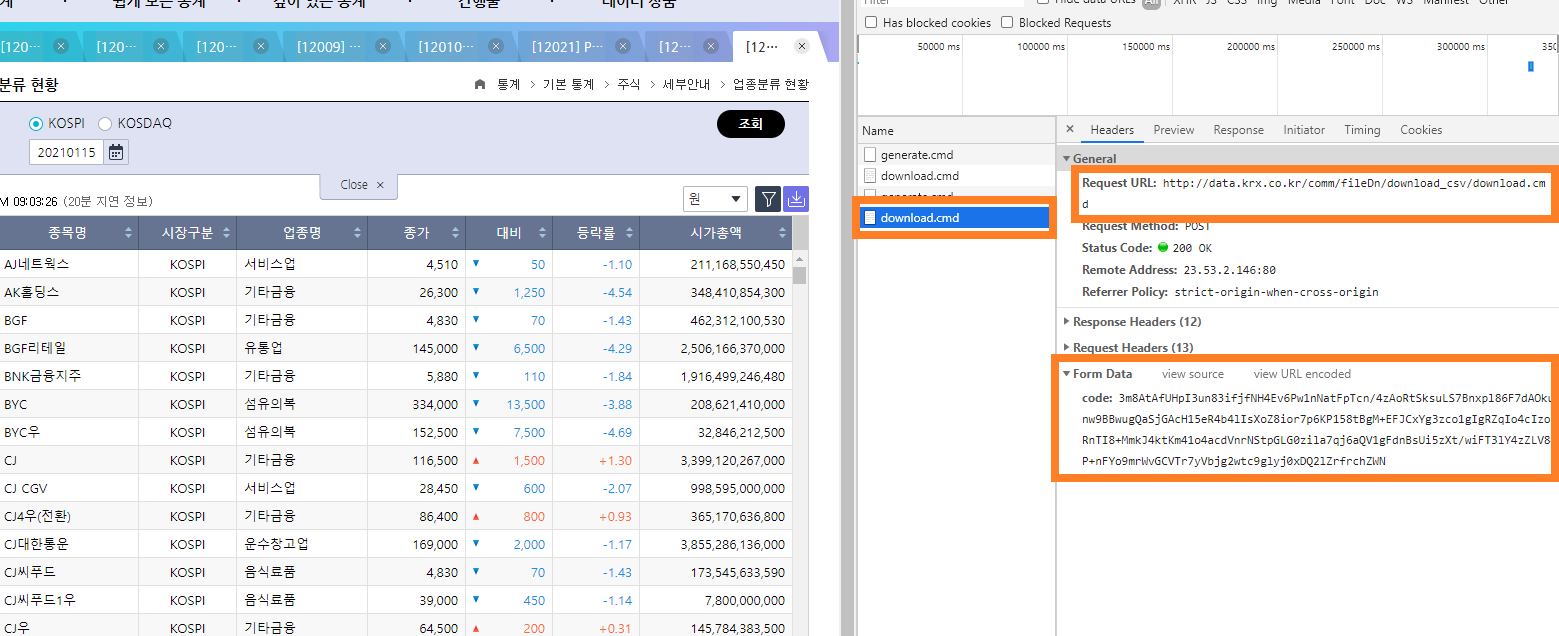
그림 5.2: OTP 제출 부분
General 항목의 Request URL은 OTP를 제출할 주소입니다. Form Data의 OTP는 1번 단계에서 부여받은 OTP에 해당합니다. 이 역시 POST 방식으로 데이터를 요청합니다.
위 과정을 코드로 나타내면 다음과 같습니다.
library(httr)
library(rvest)
library(readr)
gen_otp_url =
'http://data.krx.co.kr/comm/fileDn/GenerateOTP/generate.cmd'
gen_otp_data = list(
mktId = 'STK',
trdDd = '20210108',
money = '1',
csvxls_isNo = 'false',
name = 'fileDown',
url = 'dbms/MDC/STAT/standard/MDCSTAT03901'
)
otp = POST(gen_otp_url, query = gen_otp_data) %>%
read_html() %>%
html_text()- gen_otp_url에 원하는 항목을 제출할 URL을 입력합니다.
- 개발자 도구 화면에 나타는 쿼리 내용들을 리스트 형태로 입력합니다. 이 중 mktId의 STK는 코스피에 해당하는 내용이며, 코스닥 데이터를 받고자 할 경우 KSQ를 입력해야 합니다.
POST()함수를 통해 해당 URL에 쿼리를 전송하면 이에 해당하는 데이터를 받게 됩니다.read_html()함수를 통해 HTML 내용을 읽어옵니다.html_text()함수는 HTML 내에서 텍스트에 해당하는 부분만을 추출합니다. 이를 통해 OTP 값만 추출하게 됩니다.
위의 과정을 거쳐 생성된 OTP를 제출하면, 우리가 원하는 데이터를 다운로드할 수 있습니다.
down_url = 'http://data.krx.co.kr/comm/fileDn/download_csv/download.cmd'
down_sector_KS = POST(down_url, query = list(code = otp),
add_headers(referer = gen_otp_url)) %>%
read_html(encoding = 'EUC-KR') %>%
html_text() %>%
read_csv()- OTP를 제출할 URL을 down_url에 입력합니다.
POST()함수를 통해 위에서 부여받은 OTP 코드를 해당 URL에 제출합니다.add_headers()구문을 통해 리퍼러(referer)를 추가해야 합니다. 리퍼러란 링크를 통해서 각각의 웹사이트로 방문할 때 남는 흔적입니다. 거래소 데이터를 다운로드하는 과정을 살펴보면 첫 번째 URL에서 OTP를 부여받고, 이를 다시 두번째 URL에 제출했습니다. 그런데 이러한 과정의 흔적이 없이 OTP를 바로 두번째 URL에 제출하면 서버는 이를 로봇으로 인식해 데이터를 반환하지 않습니다. 따라서add_headers()함수를 통해 우리가 거쳐온 과정을 흔적으로 남겨 야 데이터를 반환하게 되며 첫 번째 URL을 리퍼러로 지정해줍니다.read_html()과html_text()함수를 통해 텍스트 데이터만 추출합니다. EUC-KR로 인코딩이 되어 있으므로read_html()내에 이를 입력해줍니다.read_csv()함수는 csv 형태의 데이터를 불러옵니다.
print(down_sector_KS)## # A tibble: 917 x 8
## 종목코드 종목명 시장구분 업종명 종가 대비 등락률 시가총액
## <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 095570 AJ네트웍스 KOSPI 서비스업 4540 -155 -3.3 212573219300
## 2 006840 AK홀딩스 KOSPI 기타금융 25350 150 0.6 335825671350
## 3 027410 BGF KOSPI 기타금융 4905 -25 -0.51 469490859855
## 4 282330 BGF리테일 KOSPI 유통업 141000 4500 3.3 2437030746000
## 5 138930 BNK금융지주 KOSPI 기타금융 5780 0 0 1883905721880
## 6 001460 BYC KOSPI 섬유의복 324500 10500 3.34 202687567500
## 7 001465 BYC우 KOSPI 섬유의복 157500 10000 6.78 33923137500
## 8 001040 CJ KOSPI 기타금융 102500 7600 8.01 2990642295000
## 9 079160 CJ CGV KOSPI 서비스업 26150 300 1.16 917865000000
## 10 00104K CJ4우(전환) KOSPI 기타금융 81400 5300 6.96 344038076800
## # ... with 907 more rows위 과정을 통해 down_sector 변수에는 산업별 현황 데이터가 저장되었습니다. 코스닥 시장의 데이터도 다운로드 받도록 하겠습니다.
gen_otp_data = list(
mktId = 'KSQ', # 코스닥으로 변경
trdDd = '20210108',
money = '1',
csvxls_isNo = 'false',
name = 'fileDown',
url = 'dbms/MDC/STAT/standard/MDCSTAT03901'
)
otp = POST(gen_otp_url, query = gen_otp_data) %>%
read_html() %>%
html_text()
down_sector_KQ = POST(down_url, query = list(code = otp),
add_headers(referer = gen_otp_url)) %>%
read_html(encoding = 'EUC-KR') %>%
html_text() %>%
read_csv()코스피 데이터와 코스닥 데이터를 하나로 합치도록 합니다.
down_sector = rbind(down_sector_KS, down_sector_KQ)이를 csv 파일로 저장하겠습니다.
ifelse(dir.exists('data'), FALSE, dir.create('data'))
write.csv(down_sector, 'data/krx_sector.csv')먼저 ifelse() 함수를 통해 data라는 이름의 폴더가 있으면 FALSE를 반환하고, 없으면 해당 이름으로 폴더를 생성해줍니다. 그 후 앞서 다운로드한 데이터를 data 폴더 안에 krx_sector.csv 이름으로 저장합니다. 해당 폴더를 확인해보면 데이터가 csv 형태로 저장되어 있습니다.
5.1.2 개별종목 지표 크롤링
개별종목 데이터를 크롤링하는 방법은 위와 매우 유사하며, 요청하는 쿼리 값에만 차이가 있습니다. 개발자 도구 화면을 열고 [CSV] 버튼을 클릭해 어떠한 쿼리를 요청하는지 확인합니다.
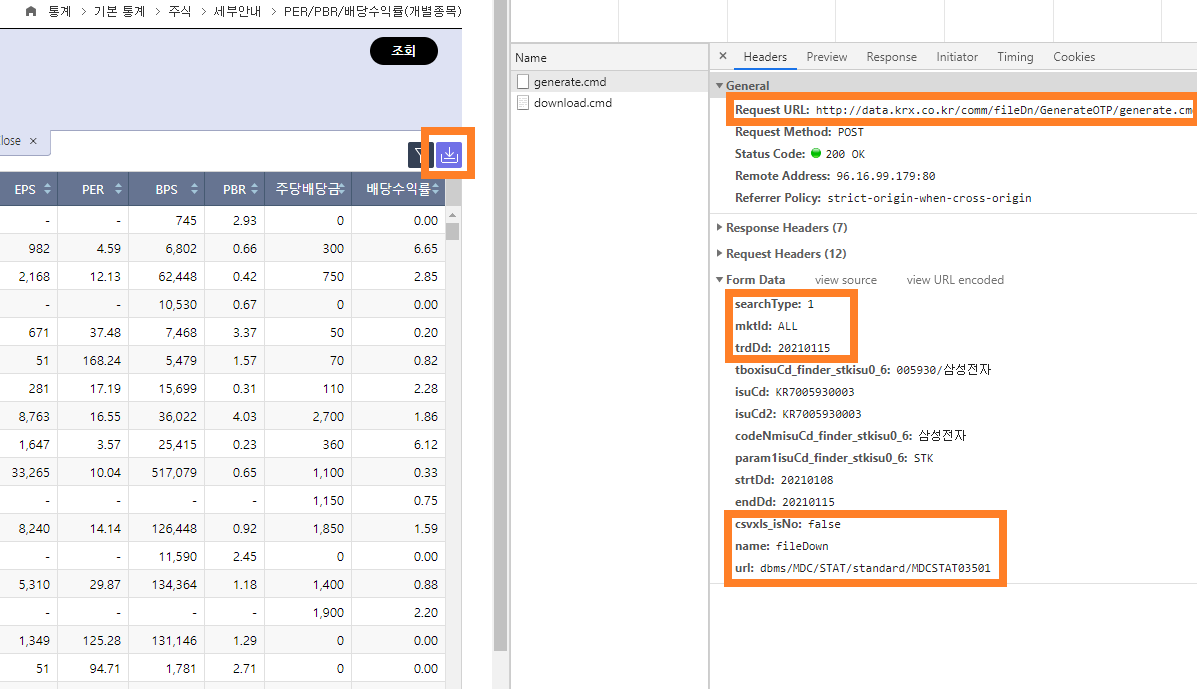
그림 5.3: 개별지표 OTP 생성 부분
이 중 tboxisuCd_finder_stkisu0_6, isu_Cd, isu_Cd2 등의 항목은 조회 구분의 개별추이 탭에 해당하는 부분이므로 우리가 원하는 전체 데이터를 받을 때는 필요하지 않은 요청값입니다. 이를 제외한 요청값을 산업별 현황 예제에 적용하면 해당 데이터 역시 손쉽게 다운로드할 수 있습니다.
library(httr)
library(rvest)
library(readr)
gen_otp_url =
'http://data.krx.co.kr/comm/fileDn/GenerateOTP/generate.cmd'
gen_otp_data = list(
searchType = '1',
mktId = 'ALL',
trdDd = '20210108',
csvxls_isNo = 'false',
name = 'fileDown',
url = 'dbms/MDC/STAT/standard/MDCSTAT03501'
)
otp = POST(gen_otp_url, query = gen_otp_data) %>%
read_html() %>%
html_text()
down_url = 'http://data.krx.co.kr/comm/fileDn/download_csv/download.cmd'
down_ind = POST(down_url, query = list(code = otp),
add_headers(referer = gen_otp_url)) %>%
read_html(encoding = 'EUC-KR') %>%
html_text() %>%
read_csv()print(down_ind)## # A tibble: 2,345 x 11
## 종목코드 종목명 종가 대비 등락률 EPS PER BPS PBR 주당배당금
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 060310 3S 2245 -45 -1.97 NA NA 745 3.01 0
## 2 095570 AJ네트웍스 4540 -155 -3.3 982 4.62 6802 0.67 300
## 3 006840 AK홀딩스 25350 150 0.6 2168 11.7 62448 0.41 750
## 4 054620 APS홀딩스 7500 -150 -1.96 NA NA 10530 0.71 0
## 5 265520 AP시스템 26000 -100 -0.38 671 38.8 7468 3.48 50
## 6 211270 AP위성 8100 -250 -2.99 51 159. 5479 1.48 70
## 7 027410 BGF 4905 -25 -0.51 281 17.5 15699 0.31 110
## 8 282330 BGF리테일 141000 4500 3.3 8763 16.1 36022 3.91 2700
## 9 138930 BNK금융지주 5780 0 0 1647 3.51 25415 0.23 360
## 10 001460 BYC 324500 10500 3.34 33265 9.75 517079 0.63 1100
## # ... with 2,335 more rows, and 1 more variable: 배당수익률 <dbl>위 과정을 통해 down_ind 변수에는 개별종목 지표 데이터가 저장되었습니다. 해당 데이터 역시 csv 파일로 저장하겠습니다.
write.csv(down_ind, 'data/krx_ind.csv')5.1.3 최근 영업일 기준 데이터 받기
위 예제의 쿼리 항목 중 date와 schdate 부분을 원하는 일자로 입력하면(예: 20190104) 해당일의 데이터를 다운로드할 수 있으며, 전 영업일 날짜를 입력하면 가장 최근의 데이터를 받을 수 있습니다. 그러나 매번 해당 항목을 입력하기는 번거로우므로 자동으로 반영되게 할 필요가 있습니다.
네이버 금융의 [국내증시 → 증시자금동향]에는 이전 2영업일에 해당하는 날짜가 있으며, 자동으로 날짜가 업데이트되어 편리합니다. 따라서 해당 부분을 크롤링해 쿼리 항목에 사용할 수 있습니다.
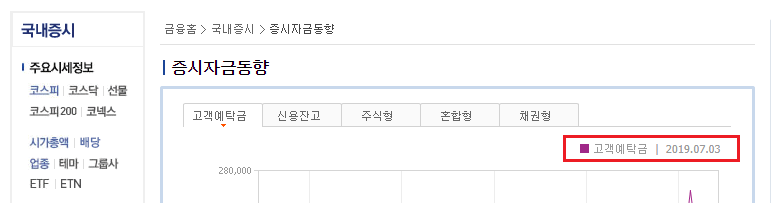
그림 5.4: 최근 영업일 부분
크롤링하고자 하는 데이터가 하나거나 소수일때는 HTML 구조를 모두 분해한 후 데이터를 추출하는 것보다 Xpath를 이용하는 것이 훨씬 효율적입니다. Xpath란 XML 중 특정 값의 태그나 속성을 찾기 쉽게 만든 주소라 생각하면 됩니다. 예를 들어 R 프로그램이 저장된 곳을 윈도우 탐색기를 이용해 이용하면 C:\Program Files\R\R-3.4.2 형태의 주소를 보이는데 이것은 윈도우의 path 문법입니다. XML 역시 이와 동일한 개념의 Xpath가 있습니다. 웹페이지에서 Xpath를 찾는 법은 다음과 같습니다.
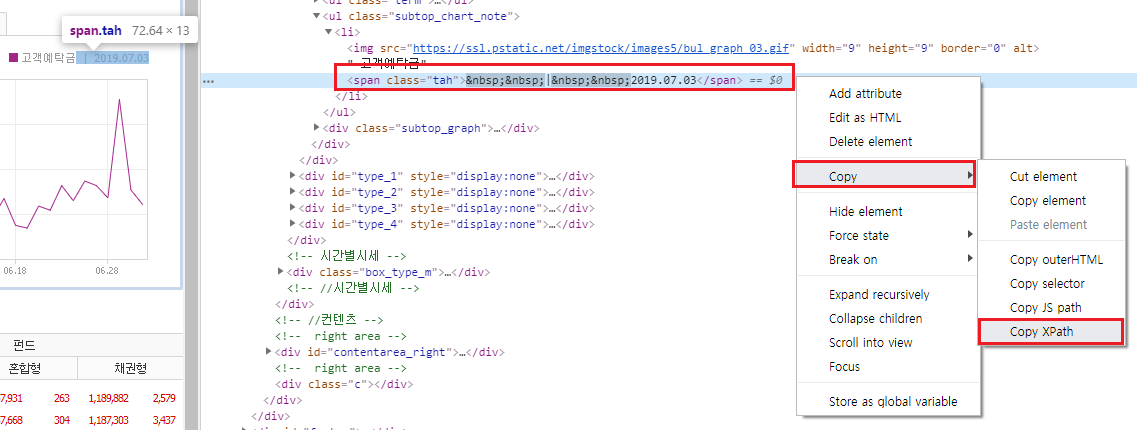
그림 5.5: Xpath 복사하기
먼저 크롤링하고자 하는 내용에 마우스 커서를 올린 채 마우스 오른쪽 버튼을 클릭한 후 [검사]를 선택합니다. 그러면 개발자 도구 화면이 열리며 해당 지점의 HTML 부분이 선택됩니다. 그 후 HTML 화면에서 마우스 오른쪽 버튼을 클릭하고 [Copy → Copy Xpath]를 선택하면 해당 지점의 Xpath가 복사됩니다.
//*[@id="type_0"]/div/ul[2]/li/span위에서 구한 날짜의 Xpath를 이용해 해당 데이터를 크롤링하겠습니다.
library(httr)
library(rvest)
library(stringr)
url = 'https://finance.naver.com/sise/sise_deposit.nhn'
biz_day = GET(url) %>%
read_html(encoding = 'EUC-KR') %>%
html_nodes(xpath =
'//*[@id="type_1"]/div/ul[2]/li/span') %>%
html_text() %>%
str_match(('[0-9]+.[0-9]+.[0-9]+') ) %>%
str_replace_all('\\.', '')
print(biz_day)## [1] "20211103"- 페이지의 url을 저장합니다.
GET()함수를 통해 해당 페이지 내용을 받습니다.read_html()함수를 이용해 해당 페이지의 HTML 내용을 읽어오며, 인코딩은 EUC-KR로 설정합니다.html_node()함수 내에 위에서 구한 Xpath를 입력해서 해당 지점의 데이터를 추출합니다.html_text()함수를 통해 텍스트 데이터만을 추출합니다.str_match()함수 내에서 정규표현식11을 이용해 숫자.숫자.숫자 형식의 데이터를 추출합니다.str_replace_all()함수를 이용해 마침표(.)를 모두 없애줍니다.
이처럼 Xpath를 이용하면 태그나 속성을 분해하지 않고도 원하는 지점의 데이터를 크롤링할 수 있습니다. 위 과정을 통해 yyyymmdd 형태의 날짜만 남게 되었습니다. 이를 위의 date와 schdate에 입력하면 산업별 현황과 개별종목 지표를 최근일자 기준으로 다운로드하게 됩니다. 전체 코드는 다음과 같습니다.
library(httr)
library(rvest)
library(stringr)
library(readr)
# 최근 영업일 구하기
url = 'https://finance.naver.com/sise/sise_deposit.nhn'
biz_day = GET(url) %>%
read_html(encoding = 'EUC-KR') %>%
html_nodes(xpath =
'//*[@id="type_1"]/div/ul[2]/li/span') %>%
html_text() %>%
str_match(('[0-9]+.[0-9]+.[0-9]+') ) %>%
str_replace_all('\\.', '')
# 코스피 업종분류 OTP 발급
gen_otp_url =
'http://data.krx.co.kr/comm/fileDn/GenerateOTP/generate.cmd'
gen_otp_data = list(
mktId = 'STK',
trdDd = biz_day, # 최근영업일로 변경
money = '1',
csvxls_isNo = 'false',
name = 'fileDown',
url = 'dbms/MDC/STAT/standard/MDCSTAT03901'
)
otp = POST(gen_otp_url, query = gen_otp_data) %>%
read_html() %>%
html_text()
# 코스피 업종분류 데이터 다운로드
down_url = 'http://data.krx.co.kr/comm/fileDn/download_csv/download.cmd'
down_sector_KS = POST(down_url, query = list(code = otp),
add_headers(referer = gen_otp_url)) %>%
read_html(encoding = 'EUC-KR') %>%
html_text() %>%
read_csv()
# 코스닥 업종분류 OTP 발급
gen_otp_data = list(
mktId = 'KSQ',
trdDd = biz_day, # 최근영업일로 변경
money = '1',
csvxls_isNo = 'false',
name = 'fileDown',
url = 'dbms/MDC/STAT/standard/MDCSTAT03901'
)
otp = POST(gen_otp_url, query = gen_otp_data) %>%
read_html() %>%
html_text()
# 코스닥 업종분류 데이터 다운로드
down_sector_KQ = POST(down_url, query = list(code = otp),
add_headers(referer = gen_otp_url)) %>%
read_html(encoding = 'EUC-KR') %>%
html_text() %>%
read_csv()
down_sector = rbind(down_sector_KS, down_sector_KQ)
ifelse(dir.exists('data'), FALSE, dir.create('data'))
write.csv(down_sector, 'data/krx_sector.csv')
# 개별종목 지표 OTP 발급
gen_otp_url =
'http://data.krx.co.kr/comm/fileDn/GenerateOTP/generate.cmd'
gen_otp_data = list(
searchType = '1',
mktId = 'ALL',
trdDd = biz_day, # 최근영업일로 변경
csvxls_isNo = 'false',
name = 'fileDown',
url = 'dbms/MDC/STAT/standard/MDCSTAT03501'
)
otp = POST(gen_otp_url, query = gen_otp_data) %>%
read_html() %>%
html_text()
# 개별종목 지표 데이터 다운로드
down_url = 'http://data.krx.co.kr/comm/fileDn/download_csv/download.cmd'
down_ind = POST(down_url, query = list(code = otp),
add_headers(referer = gen_otp_url)) %>%
read_html(encoding = 'EUC-KR') %>%
html_text() %>%
read_csv()
write.csv(down_ind, 'data/krx_ind.csv')5.1.4 거래소 데이터 정리하기
위에서 다운로드한 데이터는 중복된 열이 있으며, 불필요한 데이터 역시 있습니다. 따라서 하나의 테이블로 합친 후 정리할 필요가 있습니다. 먼저 다운로드한 csv 파일을 읽어옵니다.
down_sector = read.csv('data/krx_sector.csv', row.names = 1,
stringsAsFactors = FALSE)
down_ind = read.csv('data/krx_ind.csv', row.names = 1,
stringsAsFactors = FALSE)read.csv() 함수를 이용해 csv 파일을 불러옵니다. row.names = 1을 통해 첫 번째 열을 행 이름으로 지정하고, stringsAsFactors = FALSE를 통해 문자열 데이터가 팩터 형태로 변형되지 않게 합니다.
intersect(names(down_sector), names(down_ind))## [1] "종목코드" "종목명" "종가" "대비" "등락률"먼저 intersect() 함수를 통해 두 데이터 간 중복되는 열 이름을 살펴보면 종목코드와 종목명 등이 동일한 위치에 있습니다.
setdiff(down_sector[, '종목명'], down_ind[ ,'종목명'])## [1] "ESR켄달스퀘어리츠" "NH프라임리츠" "SK리츠"
## [4] "디앤디플랫폼리츠" "롯데리츠" "맥쿼리인프라"
## [7] "맵스리얼티1" "모두투어리츠" "미래에셋맵스리츠"
## [10] "바다로19호" "베트남개발1" "신한알파리츠"
## [13] "에이리츠" "엘브이엠씨홀딩스" "이리츠코크렙"
## [16] "이지스레지던스리츠" "이지스밸류리츠" "제이알글로벌리츠"
## [19] "케이탑리츠" "코람코에너지리츠" "프레스티지바이오파마"
## [22] "하이골드12호" "하이골드3호" "한국ANKOR유전"
## [25] "한국패러랠" "현대두산인프라코어" "GRT"
## [28] "JTC" "SBI핀테크솔루션즈" "SNK"
## [31] "골든센츄리" "글로벌에스엠" "네오이뮨텍(Reg.S)"
## [34] "로스웰" "미투젠" "소마젠"
## [37] "씨케이에이치" "애머릿지" "엑세스바이오"
## [40] "오가닉티코스메틱" "윙입푸드" "이스트아시아홀딩스"
## [43] "잉글우드랩" "컬러레이" "코오롱티슈진"
## [46] "크리스탈신소재" "헝셩그룹"setdiff() 함수를 통해 두 데이터에 공통적으로 없는 종목명, 즉 하나의 데이터에만 있는 종목을 살펴보면 위와 같습니다. 해당 종목들은 선박펀드, 광물펀드, 해외종목 등 일반적이지 않은 종목들이므로 제외하는 것이 좋습니다. 따라서 둘 사이에 공통적으로 존재하는 종목을 기준으로 데이터를 합쳐주겠습니다.
KOR_ticker = merge(down_sector, down_ind,
by = intersect(names(down_sector),
names(down_ind)),
all = FALSE
)merge() 함수는 by를 기준으로 두 데이터를 하나로 합치며, 공통으로 존재하는 종목코드, 종목명, 종가, 대비, 등락률을 기준으로 입력해줍니다. 또한 all 값을 TRUE로 설정하면 합집합을 반환하고, FALSE로 설정하면 교집합을 반환합니다. 공통으로 존재하는 항목을 원하므로 여기서는 FALSE를 입력합니다.
KOR_ticker = KOR_ticker[order(-KOR_ticker['시가총액']), ]
print(head(KOR_ticker))## 종목코드 종목명 종가 대비 등락률 시장구분 업종명 시가총액
## 326 005930 삼성전자 70400 -1100 -1.54 KOSPI 전기전자 4.203e+14
## 45 000660 SK하이닉스 105500 -2000 -1.86 KOSPI 전기전자 7.680e+13
## 837 035420 NAVER 402500 -7500 -1.83 KOSPI 서비스업 6.612e+13
## 1920 207940 삼성바이오로직스 874000 0 0.00 KOSPI 의약품 5.783e+13
## 843 035720 카카오 124500 -3500 -2.73 KOSPI 서비스업 5.545e+13
## 1062 051910 LG화학 784000 -47000 -5.66 KOSPI 화학 5.534e+13
## EPS PER BPS PBR 주당배당금 배당수익률
## 326 3841 18.33 39406 1.79 2994 4.25
## 45 6952 15.18 71275 1.48 1170 1.11
## 837 6877 58.53 44850 8.97 402 0.10
## 1920 3642 239.98 69505 12.57 0 0.00
## 843 369 337.40 14286 8.71 30 0.02
## 1062 6666 117.61 230440 3.40 10000 1.28데이터를 시가총액 기준으로 내림차순 정렬할 필요도 있습니다. order() 함수를 통해 상대적인 순서를 구할 수 있습니다. R은 기본적으로 오름차순으로 순서를 구하므로 앞에 마이너스(-)를 붙여 내림차순 형태로 바꿉니다. 결과적으로 시가총액 기준 내림차
순으로 해당 데이터가 정렬됩니다.
마지막으로 스팩, 우선주 종목 역시 제외해야 합니다.
library(stringr)
KOR_ticker[grepl('스팩', KOR_ticker[, '종목명']), '종목명'] ## [1] "엔에이치스팩19호" "엔에이치스팩20호" "삼성스팩4호"
## [4] "IBKS제14호스팩" "삼성머스트스팩5호" "하나금융17호스팩"
## [7] "엔에이치스팩17호" "대신밸런스제9호스팩" "케이비제18호스팩"
## [10] "엔에이치스팩21호" "신한제8호스팩" "상상인이안1호스팩"
## [13] "유안타제5호스팩" "대신밸런스제8호스팩" "케이비제20호스팩"
## [16] "유안타제8호스팩" "미래에셋대우스팩3호" "하나금융19호스팩"
## [19] "DB금융스팩8호" "한화플러스제1호스팩" "대신밸런스제7호스팩"
## [22] "한화플러스제2호스팩" "SK6호스팩" "유안타제7호스팩"
## [25] "한국9호스팩" "대신밸런스제10호스팩" "엔에이치스팩18호"
## [28] "하이제6호스팩" "교보10호스팩" "케이비17호스팩"
## [31] "한국제8호스팩" "IBKS제13호스팩" "유진스팩7호"
## [34] "에이치엠씨제5호스팩" "하이제5호스팩" "신한제6호스팩"
## [37] "미래에셋대우스팩 5호" "DB금융스팩9호" "하나금융15호스팩"
## [40] "신한제7호스팩" "한화에스비아이스팩" "하나머스트7호스팩"
## [43] "하나금융14호스팩" "유안타제4호스팩" "SK5호스팩"
## [46] "신영스팩6호" "에이치엠씨제4호스팩" "케이비제19호스팩"
## [49] "하나금융16호스팩" "IBKS제15호스팩" "교보9호스팩"
## [52] "상상인이안제2호스팩" "이베스트스팩5호" "IBKS제16호스팩"
## [55] "신영스팩5호" "IBKS제12호스팩" "유진스팩6호"
## [58] "이베스트이안스팩1호"KOR_ticker[str_sub(KOR_ticker[, '종목코드'], -1, -1) != 0, '종목명']## [1] "삼성전자우" "현대차2우B" "LG화학우"
## [4] "현대차우" "LG생활건강우" "LG전자우"
## [7] "아모레퍼시픽우" "미래에셋증권2우B" "삼성SDI우"
## [10] "삼성화재우" "대신증권우" "신영증권우"
## [13] "한국금융지주우" "한화3우B" "CJ4우(전환)"
## [16] "금호석유우" "두산우" "삼성전기우"
## [19] "아모레G3우(전환)" "CJ제일제당 우" "S-Oil우"
## [22] "NH투자증권우" "현대차3우B" "두산퓨얼셀1우"
## [25] "LG우" "SK이노베이션우" "대신증권2우B"
## [28] "삼성물산우B" "DL이앤씨우" "SK케미칼우"
## [31] "솔루스첨단소재1우" "신풍제약우" "CJ우"
## [34] "SK우" "아모레G우" "두산2우B"
## [37] "코오롱인더우" "미래에셋증권우" "한화투자증권우"
## [40] "부국증권우" "유한양행우" "DL우"
## [43] "GS우" "호텔신라우" "대교우B"
## [46] "두산퓨얼셀2우B" "유안타증권우" "녹십자홀딩스2우"
## [49] "롯데칠성우" "SK디스커버리우" "롯데지주우"
## [52] "솔루스첨단소재2우B" "유화증권우" "한화솔루션우"
## [55] "대한항공우" "덕성우" "BYC우"
## [58] "남양유업우" "LX하우시스우" "티와이홀딩스우"
## [61] "삼성중공우" "대덕전자1우" "세방우"
## [64] "대상우" "하이트진로2우B" "유유제약1우"
## [67] "대한제당우" "코오롱우" "넥센타이어1우B"
## [70] "삼양홀딩스우" "코리아써우" "LX홀딩스1우"
## [73] "한진칼우" "한화우" "태영건설우"
## [76] "NPC우" "삼양사우" "SK증권우"
## [79] "일양약품우" "대덕1우" "넥센우"
## [82] "크라운제과우" "성신양회우" "노루페인트우"
## [85] "DB하이텍1우" "한양증권우" "현대건설우"
## [88] "대상홀딩스우" "코오롱글로벌우" "계양전기우"
## [91] "태양금속우" "SK네트웍스우" "서울식품우"
## [94] "금호건설우" "노루홀딩스우" "동부건설우"
## [97] "대원전선우" "동원시스템즈우" "깨끗한나라우"
## [100] "현대비앤지스틸우" "루트로닉3우C" "크라운해태홀딩스우"
## [103] "하이트진로홀딩스우" "CJ씨푸드1우" "금강공업우"
## [106] "남선알미우" "유유제약2우B" "코리아써키트2우B"
## [109] "흥국화재우" "대호특수강우" "JW중외제약우"
## [112] "성문전자우" "JW중외제약2우B" "KG동부제철우"
## [115] "진흥기업우B" "동양우" "동양2우B"
## [118] "소프트센우" "신원우" "흥국화재2우B"
## [121] "진흥기업2우B" "동양3우B"grepl() 함수를 통해 종목명에 ‘스팩’이 들어가는 종목을 찾고, stringr 패키지의 str_sub() 함수를 통해 종목코드 끝이 0이 아닌 우선주 종목을 찾을 수 있습니다.
KOR_ticker = KOR_ticker[!grepl('스팩', KOR_ticker[, '종목명']), ]
KOR_ticker = KOR_ticker[str_sub(KOR_ticker[, '종목코드'], -1, -1) == 0, ]마지막으로 행 이름을 초기화한 후 정리된 데이터를 csv 파일로 저장합니다.
rownames(KOR_ticker) = NULL
write.csv(KOR_ticker, 'data/KOR_ticker.csv')5.2 WICS 기준 섹터정보 크롤링
일반적으로 주식의 섹터를 나누는 기준은 MSCI와 S&P가 개발한 GICS12를 가장 많이 사용합니다. 국내 종목의 GICS 기준 정보 역시 한국거래소에서 제공하고 있으나, 이는 독점적 지적재산으로 명시했기에 사용하는 데 무리가 있습니다. 그러나 지수제공업체인 와이즈인덱스13에서는 GICS와 비슷한 WICS 산업분류를 발표하고 있습니다. WICS를 크롤링해 필요한 정보를 수집해보겠습니다.
먼저 웹페이지에 접속해 [Index → WISE SECTOR INDEX → WICS → 에너지]를 클릭합니다. 그 후 [Components] 탭을 클릭하면 해당 섹터의 구성종목을 확인할 수 있습니다.
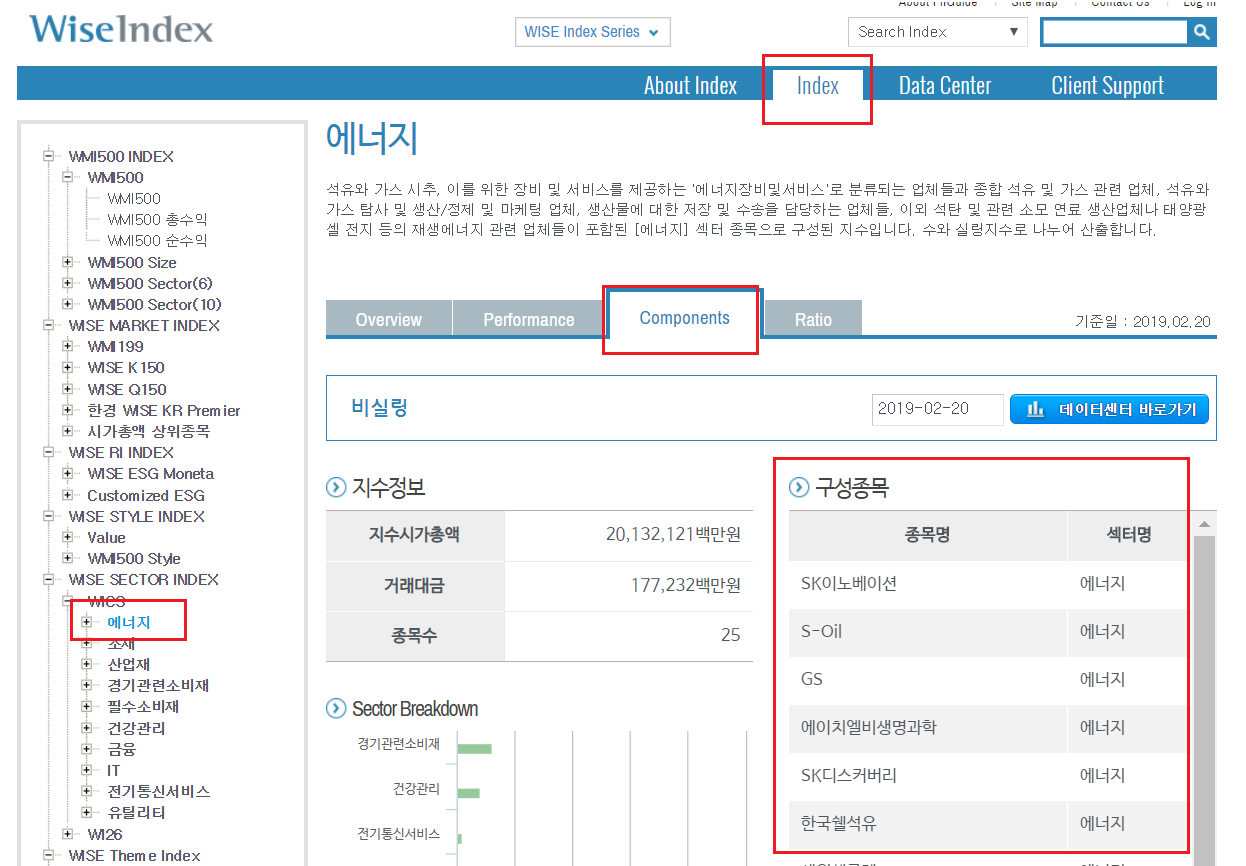
그림 5.6: WICS 기준 구성종목
개발자도구 화면(그림 5.7)을 통해 해당 페이지의 데이터전송 과정을 살펴보도록 하겠습니다.
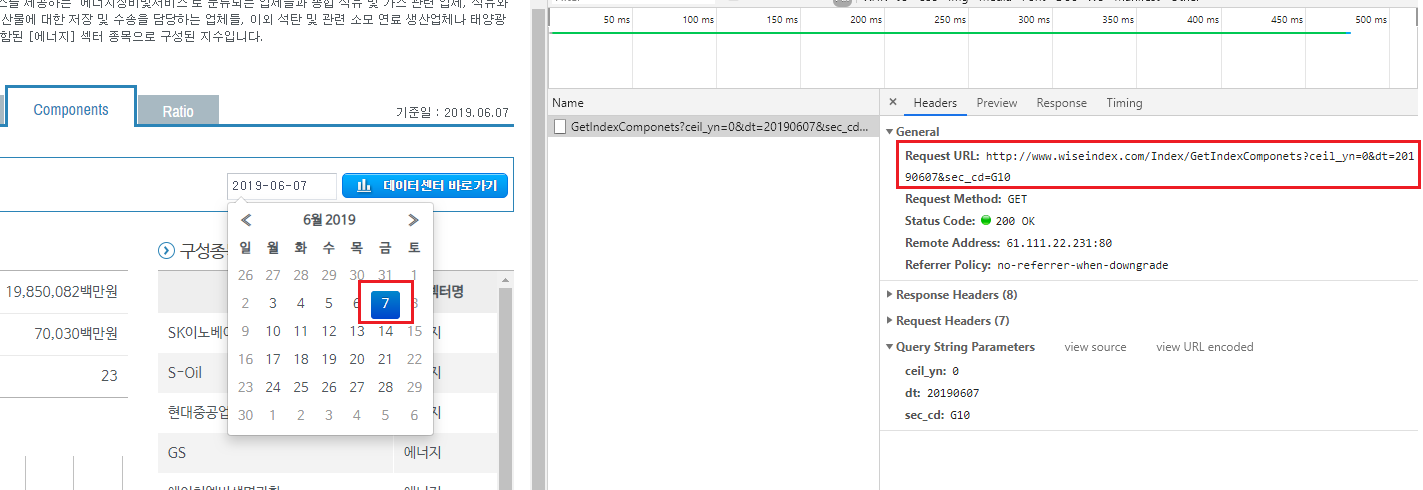
그림 5.7: WICS 페이지 개발자도구 화면
일자를 선택하면 [Network] 탭의 GetIndexComponets 항목을 통해 데이터 전송 과정이 나타납니다. Request URL의 주소를 살펴보면 다음과 같습니다.
- http://www.wiseindex.com/Index/GetIndexComponets: 데이터를 요청하는 url 입니다.
- ceil_yn = 0: 실링 여부를 나타내며, 0은 비실링을 의미합니다.
- dt=20190607: 조회일자를 나타냅니다.
- sec_cd=G10: 섹터 코드를 나타냅니다.
이번엔 위 주소의 페이지를 열어보겠습니다.

그림 5.8: WICS 데이터 페이지
글자들은 페이지에 출력된 내용이지만 매우 특이한 형태로 구성되어 있는데 이것은 JSON 형식의 데이터입니다. 기존에 우리가 살펴보았던 대부분의 웹페이지는 XML 형식으로 표현되어 있습니다. XML 형식은 문법이 복잡하고 표현 규칙이 엄격해 데이터의 용량이 커지는 단점이 있습니다. 반면 JSON 형식은 문법이 단순하고 데이터의 용량이 작아 빠른 속도로 데이터를 교환할 수 있습니다. R에서는 jsonlite 패키지의 fromJSON() 함수를 사용해 매우 손쉽게 JSON 형식의 데이터를 크롤링할 수 있습니다.
library(jsonlite)
url = 'http://www.wiseindex.com/Index/GetIndexComponets?ceil_yn=0&dt=20190607&sec_cd=G10'
data = fromJSON(url)
lapply(data, head)## $info
## $info$TRD_DT
## [1] "/Date(1559833200000)/"
##
## $info$MKT_VAL
## [1] 19850082
##
## $info$TRD_AMT
## [1] 70030
##
## $info$CNT
## [1] 23
##
##
## $list
## IDX_CD IDX_NM_KOR ALL_MKT_VAL CMP_CD CMP_KOR MKT_VAL WGT S_WGT
## 1 G10 WICS 에너지 19850082 096770 SK이노베이션 9052841 45.61 45.61
## 2 G10 WICS 에너지 19850082 010950 S-Oil 3403265 17.14 62.75
## 3 G10 WICS 에너지 19850082 267250 현대중공업지주 2873204 14.47 77.23
## 4 G10 WICS 에너지 19850082 078930 GS 2491805 12.55 89.78
## 5 G10 WICS 에너지 19850082 067630 에이치엘비생명과학 624986 3.15 92.93
## 6 G10 WICS 에너지 19850082 006120 SK디스커버리 257059 1.30 94.22
## CAL_WGT SEC_CD SEC_NM_KOR SEQ TOP60 APT_SHR_CNT
## 1 1 G10 에너지 1 2 56403994
## 2 1 G10 에너지 2 2 41655633
## 3 1 G10 에너지 3 2 9283372
## 4 1 G10 에너지 4 2 49245150
## 5 1 G10 에너지 5 2 39307272
## 6 1 G10 에너지 6 2 10470820
##
## $sector
## SEC_CD SEC_NM_KOR SEC_RATE IDX_RATE
## 1 G25 경기관련소비재 16.05 0
## 2 G35 건강관리 9.27 0
## 3 G50 커뮤니케이션서비스 2.26 0
## 4 G40 금융 10.31 0
## 5 G10 에너지 2.37 100
## 6 G20 산업재 12.68 0
##
## $size
## SEC_CD SEC_NM_KOR SEC_RATE IDX_RATE
## 1 WMI510 WMI500 대형주 69.40 89.78
## 2 WMI520 WMI500 중형주 13.56 4.44
## 3 WMI530 WMI500 소형주 17.04 5.78$list 항목에는 해당 섹터의 구성종목 정보가 있으며, $sector 항목을 통해 다른 섹터의 코드도 확인할 수 있습니다. for loop 구문을 이용해 URL의 sec_cd=에 해당하는 부분만 변경하면 모든 섹터의 구성종목을 매우 쉽게 얻을 수 있습니다.
sector_code = c('G25', 'G35', 'G50', 'G40', 'G10',
'G20', 'G55', 'G30', 'G15', 'G45')
data_sector = list()
for (i in sector_code) {
url = paste0(
'http://www.wiseindex.com/Index/GetIndexComponets',
'?ceil_yn=0&dt=',biz_day,'&sec_cd=',i)
data = fromJSON(url)
data = data$list
data_sector[[i]] = data
Sys.sleep(1)
}
data_sector = do.call(rbind, data_sector)해당 데이터를 csv 파일로 저장해주도록 합니다.
write.csv(data_sector, 'data/KOR_sector.csv')특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식 언어↩︎
https://en.wikipedia.org/wiki/Global_Industry_Classification_Standard↩︎