Chapter 8 데이터 분석 및 시각화하기
데이터 수집 및 정리가 끝났다면, 내가 가지고 있는 데이터가 어떠한 특성을 가지고 있는지에 대한 분석 및 시각화 과정, 즉 탐색적 데이터 분석(Exploratory Data Analysis)을 할 필요가 있습니다. 이 과정을 통해 데이터를 더 잘 이해할 수 있으며, 극단치나 결측치 등 데이터가 가지고 있는 잠재적인 문제를 발견하고 이를 어떻게 처리할지 고민할 수 있습니다.
이 CHAPTER에서는 dplyr 패키지를 이용한 데이터 분석과 ggplot2 패키지를 이용한 데이터 시각화에 대해 알아보겠습니다.
8.1 종목정보 데이터 분석
먼저 거래소를 통해 수집한 산업별 현황과 개별지표를 정리한 파일, WICS 기준 섹터 지표를 정리한 파일을 통해 국내 상장종목의 데이터를 분석해보겠습니다.
library(stringr)
KOR_ticker = read.csv('data/KOR_ticker.csv', row.names = 1,
stringsAsFactors = FALSE)
KOR_sector = read.csv('data/KOR_sector.csv', row.names = 1,
stringsAsFactors = FALSE)
KOR_ticker$'종목코드' =
str_pad(KOR_ticker$'종목코드', 6,'left', 0)
KOR_sector$'CMP_CD' =
str_pad(KOR_sector$'CMP_CD', 6, 'left', 0)각 파일을 불러온 후 티커에 해당하는 종목코드와 CMP_CD 열을 6자리 숫자로 만들어줍니다.
이제 dplyr 패키지의 여러 함수들을 이용해 데이터를 분석해보겠습니다. 해당 패키지는 데이터 처리에 특화된 패키지이며, C++로 작성되어 매우 빠른 처리 속도를 자랑합니다. 또한 문법이 SQL과 매우 비슷해 함수의 내용을 직관적으로 이해할 수 있습니다.
8.1.1 *_join: 데이터 합치기
두 테이블을 하나로 합치기 위해 *_join() 함수를 이용합니다. 해당 함수는 기존에 살펴본 merge() 함수와 동일하며, 합치는 방법은 그림 8.1과 표 8.1과 같이 크게 네가지 종류가 있습니다.
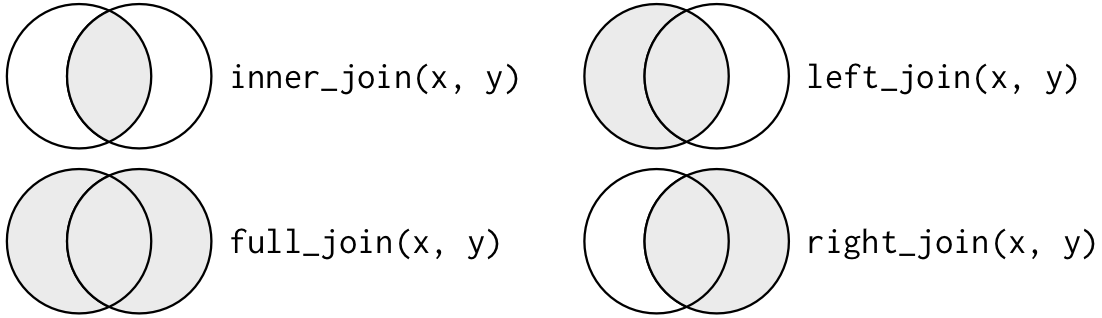
그림 8.1: *_ join() 함수의 종류
| 함수 | 내용 |
|---|---|
| inner_join() | 교집합 |
| full_join() | 합집합 |
| left_join() | 좌측 기준 |
| right_join() | 우측 기준 |
이 중 거래소 티커 기준으로 데이터를 맞추기 위해 left_join() 함수를 사용해 두 데이터를 합치겠습니다.
library(dplyr)
data_market = left_join(KOR_ticker, KOR_sector,
by = c('종목코드' = 'CMP_CD',
'종목명' = 'CMP_KOR'))
head(data_market)## 종목코드 종목명 종가 대비 등락률 시장구분 업종명 시가총액
## 1 005930 삼성전자 70400 -1100 -1.54 KOSPI 전기전자 4.203e+14
## 2 000660 SK하이닉스 105500 -2000 -1.86 KOSPI 전기전자 7.680e+13
## 3 035420 NAVER 402500 -7500 -1.83 KOSPI 서비스업 6.612e+13
## 4 207940 삼성바이오로직스 874000 0 0.00 KOSPI 의약품 5.783e+13
## 5 035720 카카오 124500 -3500 -2.73 KOSPI 서비스업 5.545e+13
## 6 051910 LG화학 784000 -47000 -5.66 KOSPI 화학 5.534e+13
## EPS PER BPS PBR 주당배당금 배당수익률 IDX_CD IDX_NM_KOR
## 1 3841 18.33 39406 1.79 2994 4.25 G45 WICS IT
## 2 6952 15.18 71275 1.48 1170 1.11 G45 WICS IT
## 3 6877 58.53 44850 8.97 402 0.10 G50 WICS 커뮤니케이션서비스
## 4 3642 239.98 69505 12.57 0 0.00 G35 WICS 건강관리
## 5 369 337.40 14286 8.71 30 0.02 G50 WICS 커뮤니케이션서비스
## 6 6666 117.61 230440 3.40 10000 1.28 G15 WICS 소재
## ALL_MKT_VAL MKT_VAL WGT S_WGT CAL_WGT SEC_CD SEC_NM_KOR SEQ TOP60
## 1 551957421 315204519 57.11 57.11 1 G45 IT 1 2
## 2 551957421 56835145 10.30 67.40 1 G45 IT 2 2
## 3 180662521 51570493 28.55 28.55 1 G50 커뮤니케이션서비스 1 4
## 4 136785726 14457053 10.57 26.66 1 G35 건강관리 2 27
## 5 180662521 38258764 21.18 49.72 1 G50 커뮤니케이션서비스 2 4
## 6 122898119 35420414 28.82 28.82 1 G15 소재 1 8
## APT_SHR_CNT
## 1 4477336913
## 2 538721750
## 3 128125448
## 4 16541250
## 5 307299311
## 6 45179100left_join() 함수를 이용해 KOR_ticker와 KOR_sector 데이터를 합쳐줍니다. by 인자는 데이터를 합치는 기준점을 의미하며, x 데이터(KOR_ticker)의 종목코드와 y 데이터(KOR_sector)의 CMP_CD는 같음을, x 데이터의 종목명과 y 데이터의 CMP_KOR는 같음을 정의합니다.
8.1.2 glimpse(): 데이터 구조 확인하기
glimpse(data_market)## Rows: 2,237
## Columns: 26
## $ 종목코드 <chr> "005930", "000660", "035420", "2~
## $ 종목명 <chr> "삼성전자", "SK하이닉스", "NAVE~
## $ 종가 <dbl> 70400, 105500, 402500, 874000,~
## $ 대비 <int> -1100, -2000, -7500, 0, -3500,~
## $ 등락률 <dbl> -1.54, -1.86, -1.83, 0.00, -2.7~
## $ 시장구분 <chr> "KOSPI", "KOSPI", "KOSPI", "KOSP~
## $ 업종명 <chr> "전기전자", "전기전자", "서비스~
## $ 시가총액 <dbl> 4.203e+14, 7.680e+13, 6.612e+13,~
## $ EPS <int> 3841, 6952, 6877, 3642, 369,~
## $ PER <dbl> 18.33, 15.18, 58.53, 239.98,~
## $ BPS <int> 39406, 71275, 44850, 69505, ~
## $ PBR <dbl> 1.79, 1.48, 8.97, 12.57, 8.7~
## $ 주당배당금 <int> 2994, 1170, 402, 0, 30, 10000, 10~
## $ 배당수익률 <dbl> 4.25, 1.11, 0.10, 0.00, 0.02, 1.2~
## $ IDX_CD <chr> "G45", "G45", "G50", "G35", ~
## $ IDX_NM_KOR <chr> "WICS IT", "WICS IT", "WICS ~
## $ ALL_MKT_VAL <int> 551957421, 551957421, 180662~
## $ MKT_VAL <int> 315204519, 56835145, 5157049~
## $ WGT <dbl> 57.11, 10.30, 28.55, 10.57, ~
## $ S_WGT <dbl> 57.11, 67.40, 28.55, 26.66, ~
## $ CAL_WGT <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1~
## $ SEC_CD <chr> "G45", "G45", "G50", "G35", ~
## $ SEC_NM_KOR <chr> "IT", "IT", "커뮤니케이션서~
## $ SEQ <int> 1, 2, 1, 2, 2, 1, 3, 1, 2, 1~
## $ TOP60 <int> 2, 2, 4, 27, 4, 8, 2, 9, 9, ~
## $ APT_SHR_CNT <dbl> 4477336913, 538721750, 12812~glimpse() 함수는 데이터 내용, 구조, 형식을 확인하는 함수입니다. 기본 함수인 str()과 그 역할은 비슷하지만, tidy 형태로 결과물이 훨씬 깔끔하게 출력됩니다. 총 관측값 및 열의 개수, 각 열의 이름과 데이터 형식, 앞부분 데이터를 확인할 수 있습니다.
8.1.3 rename(): 열 이름 바꾸기
head(names(data_market), 15)## [1] "종목코드" "종목명" "종가" "대비" "등락률"
## [6] "시장구분" "업종명" "시가총액" "EPS" "PER"
## [11] "BPS" "PBR" "주당배당금" "배당수익률" "IDX_CD"data_market = data_market %>%
rename(`배당수익률(%)` = `배당수익률`)
head(names(data_market), 15)## [1] "종목코드" "종목명" "종가" "대비"
## [5] "등락률" "시장구분" "업종명" "시가총액"
## [9] "EPS" "PER" "BPS" "PBR"
## [13] "주당배당금" "배당수익률(%)" "IDX_CD"rename() 함수는 열 이름을 바꾸는 함수로서, rename(tbl, new_name = old_name) 형태로 입력합니다. 위의 경우 배당수익률 열 이름이 배당수익률(%)로 변경되었습니다.
8.1.4 distinct(): 고유한 값 확인
data_market %>%
distinct(SEC_NM_KOR) %>% c() ## $SEC_NM_KOR
## [1] "IT" "커뮤니케이션서비스" "건강관리"
## [4] "소재" "경기관련소비재" "금융"
## [7] NA "에너지" "산업재"
## [10] "유틸리티" "필수소비재"distinct() 함수는 고유한 값을 반환하며, 기본 함수 중 unique()와 동일한 기능을 합니다. 데이터의 섹터 정보를 확인해보면, WICS 기준 10개 섹터 및 섹터 정보가 없는 종목인 NA 값이 있습니다.
8.1.5 select(): 원하는 열만 선택
data_market %>%
select(`종목명`) %>% head()## 종목명
## 1 삼성전자
## 2 SK하이닉스
## 3 NAVER
## 4 삼성바이오로직스
## 5 카카오
## 6 LG화학data_market %>%
select(`종목명`, `PBR`, `SEC_NM_KOR`) %>% head()## 종목명 PBR SEC_NM_KOR
## 1 삼성전자 1.79 IT
## 2 SK하이닉스 1.48 IT
## 3 NAVER 8.97 커뮤니케이션서비스
## 4 삼성바이오로직스 12.57 건강관리
## 5 카카오 8.71 커뮤니케이션서비스
## 6 LG화학 3.40 소재select() 함수는 원하는 열을 선택해주는 함수이며, 원하는 열 이름을 입력하면 됩니다. 하나의 열뿐만 아니라 다수의 열을 입력하면 해당 열들이 선택됩니다.
data_market %>%
select(starts_with('시')) %>% head()## 시장구분 시가총액
## 1 KOSPI 4.203e+14
## 2 KOSPI 7.680e+13
## 3 KOSPI 6.612e+13
## 4 KOSPI 5.783e+13
## 5 KOSPI 5.545e+13
## 6 KOSPI 5.534e+13data_market %>%
select(ends_with('R')) %>% head()## PER PBR IDX_NM_KOR SEC_NM_KOR
## 1 18.33 1.79 WICS IT IT
## 2 15.18 1.48 WICS IT IT
## 3 58.53 8.97 WICS 커뮤니케이션서비스 커뮤니케이션서비스
## 4 239.98 12.57 WICS 건강관리 건강관리
## 5 337.40 8.71 WICS 커뮤니케이션서비스 커뮤니케이션서비스
## 6 117.61 3.40 WICS 소재 소재data_market %>%
select(contains('가')) %>% head()## 종가 시가총액
## 1 70400 4.203e+14
## 2 105500 7.680e+13
## 3 402500 6.612e+13
## 4 874000 5.783e+13
## 5 124500 5.545e+13
## 6 784000 5.534e+13해당 함수는 다양한 응용 기능도 제공합니다. starts_with()는 특정 문자로 시작하는 열들을 선택하고, ends_with()는 특정 문자로 끝나는 열들을 선택하며, contains()는 특정 문자가 포함되는 열들을 선택합니다.
8.1.6 mutate(): 열 생성 및 데이터 변형
data_market = data_market %>%
mutate(`PBR` = as.numeric(PBR),
`PER` = as.numeric(PER),
`ROE` = PBR / PER,
`ROE` = round(ROE, 4),
`size` = ifelse(`시가총액` >=
median(`시가총액`, na.rm = TRUE),
'big', 'small')
)
data_market %>%
select(`종목명`, `ROE`, `size`) %>% head()## 종목명 ROE size
## 1 삼성전자 0.0977 big
## 2 SK하이닉스 0.0975 big
## 3 NAVER 0.1533 big
## 4 삼성바이오로직스 0.0524 big
## 5 카카오 0.0258 big
## 6 LG화학 0.0289 bigmutate() 함수는 원하는 형태로 열을 생성하거나 변형하는 함수입니다. 위 예제에 서는 먼저 PBR과 PER 열을 as.numeric() 함수를 통해 숫자형으로 변경한 후 PBR을 PER로 나눈 값을 ROE 열에 생성합니다. 그 후 round() 함수를 통해 ROE 값을 반올림하며, ifelse() 함수를 통해 시가총액의 중앙값보다 큰 기업은 big, 아닐 경우 small임을 size 열에 저장합니다.
이 외에도 mutate_*() 계열 함수에는 mutate_all(), mutate_if(), mutate_at() 처럼 각 상황에 맞게 쓸 수 있는 다양한 함수들이 있습니다.
8.1.7 filter(): 조건을 충족하는 행 선택
data_market %>%
select(`종목명`, `PBR`) %>%
filter(`PBR` < 1) %>% head()## 종목명 PBR
## 1 현대차 0.83
## 2 POSCO 0.59
## 3 현대모비스 0.72
## 4 KB금융 0.54
## 5 삼성물산 0.73
## 6 신한지주 0.46data_market %>%
select(`종목명`, `PBR`, `PER`, `ROE`) %>%
filter(PBR < 1 & PER < 20 & ROE > 0.1 ) %>% head()## 종목명 PBR PER ROE
## 1 미래에셋증권 0.75 7.21 0.1040
## 2 한국금융지주 0.96 5.91 0.1624
## 3 DB손해보험 0.64 6.36 0.1006
## 4 메리츠증권 0.76 5.43 0.1400
## 5 KCC 0.58 4.39 0.1321
## 6 키움증권 0.94 3.48 0.2701filter() 함수는 조건을 충족하는 부분의 데이터를 반환하는 함수입니다. 첫 번째 예제와 같이 PBR이 1 미만인 단일 조건을 입력할 수도 있으며, 두 번째 예제와 같이 PBR 1 미만, PER 20 미만, ROE 0.1 초과 등 복수 조건을 입력할 수도 있습니다.
8.1.8 summarize(): 요약 통곗값 계산
data_market %>%
summarize(PBR_max = max(PBR, na.rm = TRUE),
PBR_min = min(PBR, na.rm = TRUE))## PBR_max PBR_min
## 1 680 0.15summarize() 혹은 summarise() 함수는 원하는 요약 통곗값을 계산합니다. PBR_max는 PBR 열에서 최댓값을, PBR_min은 최솟값을 계산해줍니다.
8.1.9 arrange(): 데이터 정렬
data_market %>%
select(PBR) %>%
arrange(PBR) %>%
head(5)## PBR
## 1 0.15
## 2 0.19
## 3 0.20
## 4 0.21
## 5 0.24data_market %>%
select(ROE) %>%
arrange(desc(ROE)) %>%
head(5)## ROE
## 1 2.5574
## 2 2.4804
## 3 2.1714
## 4 1.0249
## 5 0.8228arrange() 함수는 선택한 열을 기준으로 데이터를 정렬해주며, 오름차순으로 정렬합니다. 내림차순으로 데이터를 정렬하려면 arrange() 내에 desc() 함수를 추가로 입력해주면 됩니다.
8.1.10 row_number(): 순위 계산
data_market %>%
mutate(PBR_rank = row_number(PBR)) %>%
select(`종목명`, PBR, PBR_rank) %>%
arrange(PBR) %>%
head(5)## 종목명 PBR PBR_rank
## 1 지스마트글로벌 0.15 1
## 2 세원정공 0.19 2
## 3 경동인베스트 0.20 3
## 4 한국전력 0.21 4
## 5 한화생명 0.24 5data_market %>%
mutate(ROE_rank = row_number(desc(ROE))) %>%
select(`종목명`, ROE, ROE_rank) %>%
arrange(desc(ROE)) %>%
head(5)## 종목명 ROE ROE_rank
## 1 샘씨엔에스 2.5574 1
## 2 이지바이오 2.4804 2
## 3 솔브레인홀딩스 2.1714 3
## 4 한컴라이프케어 1.0249 4
## 5 에스디바이오센서 0.8228 5row_number() 함수는 선택한 열의 순위를 구해줍니다. 기본적으로 오름차순으로 순위를 구하며, 내림차순으로 순위를 구하려면 desc() 함수를 추가해주면 됩니다.
순위를 구하는 함수는 이 외에도 min_rank(), dense_rank(), percent_rank()가 있습니다.
8.1.11 ntile(): 분위수 계산
data_market %>%
mutate(PBR_tile = ntile(PBR, n = 5)) %>%
select(PBR, PBR_tile) %>%
head()## PBR PBR_tile
## 1 1.79 3
## 2 1.48 3
## 3 8.97 5
## 4 12.57 5
## 5 8.71 5
## 6 3.40 4ntile() 함수는 분위수를 계산해주며, n 인자를 통해 몇 분위로 나눌지 선택할 수 있습니다. 해당 함수 역시 오름차순으로 분위수를 나눕니다.
8.1.12 group_by(): 그룹별로 데이터를 묶기
data_market %>%
group_by(`SEC_NM_KOR`) %>%
summarize(n())## # A tibble: 11 x 2
## SEC_NM_KOR `n()`
## <chr> <int>
## 1 IT 579
## 2 건강관리 288
## 3 경기관련소비재 342
## 4 금융 79
## 5 산업재 349
## 6 소재 228
## 7 에너지 28
## 8 유틸리티 19
## 9 커뮤니케이션서비스 116
## 10 필수소비재 103
## 11 <NA> 106group_by() 함수는 선택한 열 중 동일한 데이터를 기준으로 데이터를 묶어줍니다. 위 예제에서는 섹터를 나타내는 SEC_NM_KOR 기준으로 데이터를 묶었으며, n() 함수를 통해 해당 그룹 내 데이터의 개수를 구할 수 있습니다.
data_market %>%
group_by(`SEC_NM_KOR`) %>%
summarize(PBR_median = median(PBR, na.rm = TRUE)) %>%
arrange(PBR_median)## # A tibble: 11 x 2
## SEC_NM_KOR PBR_median
## <chr> <dbl>
## 1 유틸리티 0.65
## 2 금융 0.745
## 3 필수소비재 1.05
## 4 산업재 1.21
## 5 소재 1.24
## 6 경기관련소비재 1.33
## 7 에너지 1.46
## 8 IT 2.07
## 9 <NA> 2.15
## 10 커뮤니케이션서비스 2.9
## 11 건강관리 3.12위 예제는 섹터를 기준으로 데이터를 묶은 후 summarize()를 통해 각 섹터에 속하는 종목의 PBR 중앙값을 구한 후 정렬했습니다.
data_market %>%
group_by(`시장구분`, `SEC_NM_KOR`) %>%
summarize(PBR_median = median(PBR, na.rm = TRUE)) %>%
arrange(PBR_median)## # A tibble: 22 x 3
## # Groups: 시장구분 [2]
## 시장구분 SEC_NM_KOR PBR_median
## <chr> <chr> <dbl>
## 1 KOSPI 금융 0.62
## 2 KOSPI 유틸리티 0.65
## 3 KOSPI 필수소비재 0.825
## 4 KOSPI 에너지 0.87
## 5 KOSPI 경기관련소비재 1.02
## 6 KOSPI 산업재 1.02
## 7 KOSPI 소재 1.07
## 8 KOSDAQ 유틸리티 1.34
## 9 KOSDAQ 소재 1.42
## 10 KOSDAQ 산업재 1.45
## # ... with 12 more rows위 예제는 시장과 섹터를 기준으로 데이터를 그룹화한 후 각 그룹별 PBR 중앙값을 구했습니다. 이처럼 그룹은 하나만이 아닌 원하는 만큼 나눌 수 있습니다.
8.2 ggplot() 기초
R에서 기본적으로 제공하는 plot() 함수를 이용해도 시각화가 충분히 가능합니다. 그러나 데이터 과학자들에게 가장 많이 사랑받는 패키지 중 하나인 ggplot2 패키지의 ggplot() 함수를 사용하면 그림을 훨씬 아름답게 표현할 수 있으며 다양한 기능들을 매우 쉽게 사용할 수도 있습니다.
ggplot() 함수는 플러스(+) 기호를 사용한다는 점과 문법이 다소 어색하다는 점 때문에 처음에 배우기가 쉽지는 않습니다. 그러나 해당 패키지의 근본이 되는 철학인 그래픽 문법(The Grammar of Graphics)를 이해하고 조금만 연습해본다면, 충분히 손쉽게 사용이 가능합니다.
그래픽 문법(Grammar of Graphics)은 릴랜드 윌킨스(Leland Wilkinson)의 책 The Grammar of Graphics(Wilkinson 2012)에서 따온 것으로써, 데이터를 어떻게 표현할 것인지에 대한 내용입니다.
문법은 언어의 표현을 풍부하게 만든다. 단어만 있고 문법이 없는 언어가 있다면(단어 = 문장), 오직 단어의 갯수만큼만 생각을 표현할 수 있다. 문장 내에서 단어가 어떻게 구성되는 지를 규정함으로써, 문법은 언어의 범위를 확장한다.
— Leland Wilkinson, 《The Grammar of Graphics》
그래픽 문법에서 말하는 요소는 다음과 같습니다.
- Data: 시각화에 사용될 데이터
- Aesthetics: 데이터를 나타내는 시각적인 요소(x축, y축, 사이즈, 색깔, 모양 등)
- Geometrics: 데이터를 나타내는 도형
- Facets: 하위 집합으로 분할하여 시각화
- Statistics: 통계값을 표현
- Coordinates: 데이터를 표현 할 이차원 좌표계
- Theme: 그래프를 꾸밈
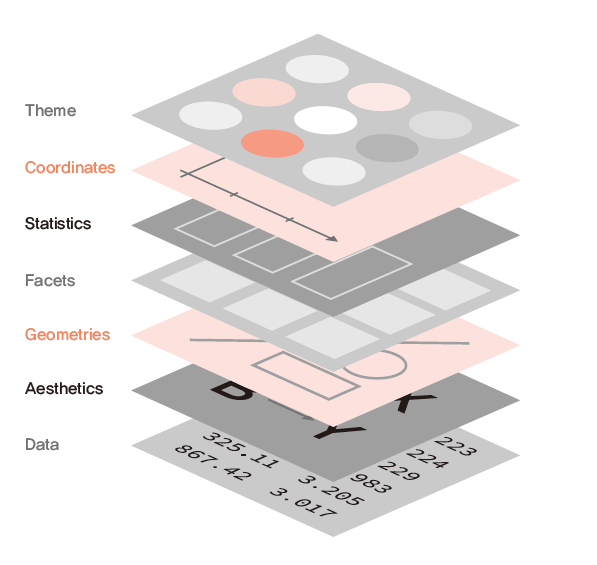
그림 8.2: The Grammar of Graphics
ggplot2 패키지의 앞글자가 gg인 것에서 알 수 있듯이, 해당 패키지는 그래픽 문법을 토대로 시각화를 표현하며, 전반적인 시각화의 순서는 그래픽 문법의 순서와 같습니다. ggplot2 패키지의 특징은 각 요소를 연결할 때 플러스(+) 기호를 사용한다는 점이며, 이는 그래픽 문법의 순서에 따라 요소들을 쌓아나간 후 최종적인 그래픽을 완성하는 패키지의 특성 때문입니다.
본 책에서 설명하는 것 외에도 다양한 예제와 함수가 궁금하신 분은 아래 링크를 참조하시길 바랍니다.
8.2.1 diamonds 데이터셋
ggplot2 패키지에는 데이터분석 및 시각화 연습을 위한 각종 데이터셋이 있으며, 그 중에서도 diamonds 데이터셋이 널리 사용됩니다. 먼저 해당 데이터를 불러오도록 하겠습니다.
library(ggplot2)
data(diamonds)
head(diamonds)## # A tibble: 6 x 10
## carat cut color clarity depth table price x y z
## <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
## 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
## 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
## 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
## 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
## 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48데이터의 각 변수는 다음과 같습니다.
- carat: 다이아몬드 무게
- cut: 컷팅의 가치
- color: 다이아몬스 색상
- clarity: 깨끗한 정도
- depth: 깊이 비율, z / mean(x, y)
- table: 가장 넓은 부분의 너비 대비 다이아몬드 꼭대기의 너비
- price: 가격
- x: 길이
- y: 너비
- z: 깊이
8.2.2 Data, Aesthetics, Geometrics
Data는 사용될 데이터이며, Aesthetics는 x축, y축, 사이즈 등 시각적인 요소를 의미합니다.
ggplot(data = diamonds, aes(x = carat, y = price))
ggplot()함수 내부의 data에 diamonds를 지정해줍니다.aes()함수를 통해 데이터를 매핑해주며 x축에 carat을, y축에 price를 지정해줍니다.
x축과 y축에 우리가 매핑한 carat과 price가 표현되었지만, 어떠한 모양(Geometrics)으로 시각화를 할지 정의하지 않았으므로 빈 그림이 생성됩니다. 다음으로 Geometrics을 통해 데이터를 그림으로 표현해주도록 하겠습니다.
ggplot(data = diamonds, aes(x = carat, y = price)) +
geom_point()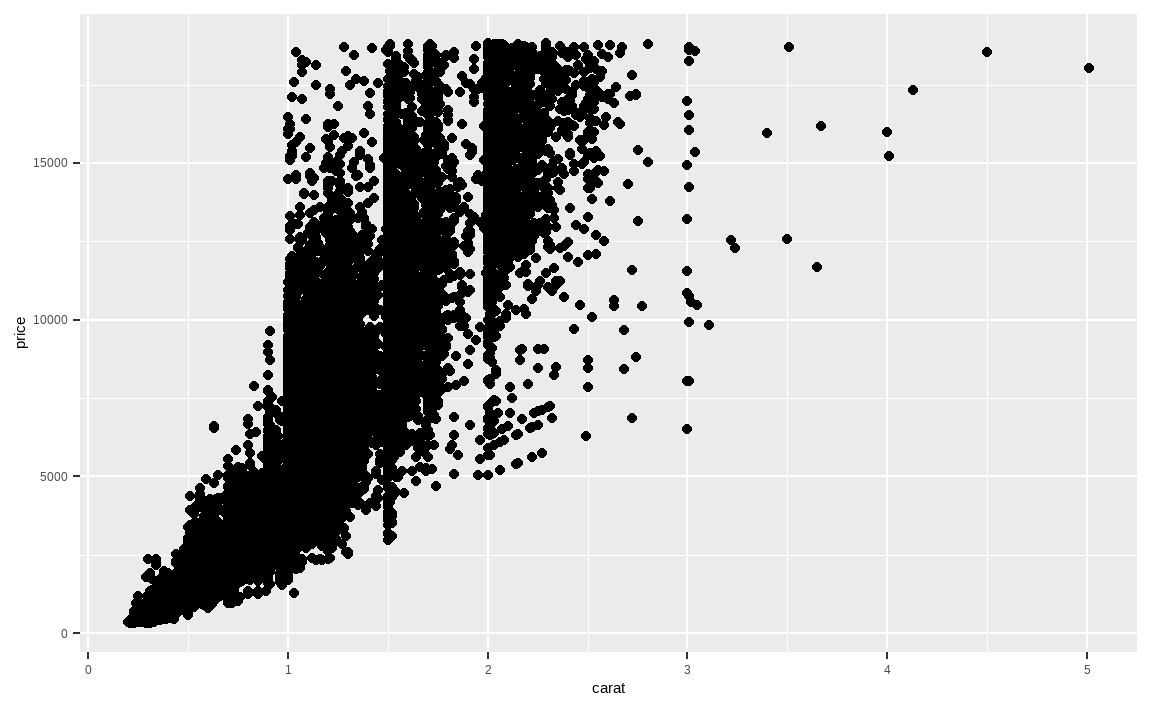
사전에 정의된 Data와 Aesthetics 위에, 플러스(+) 기호를 통해 geom_point() 함수를 입력하여 산점도가 표현되었습니다. geom은 Geometrics의 약자이며, 이처럼 geom_*() 함수를 통해 원하는 형태로 시각화를 할 수 있습니다.
일반적으로 Data는 ggplot() 함수 내에서 정의하기 보다는, dplyr 패키지의 함수들을 이용하여 데이터를 가공한 후 파이프 오퍼레이터를 통해 연결합니다. 이에 대해서는 나중에 다시 다루도록 하겠습니다.
library(magrittr)
diamonds %>%
ggplot(aes(x = carat, y = price)) +
geom_point(aes(color = cut))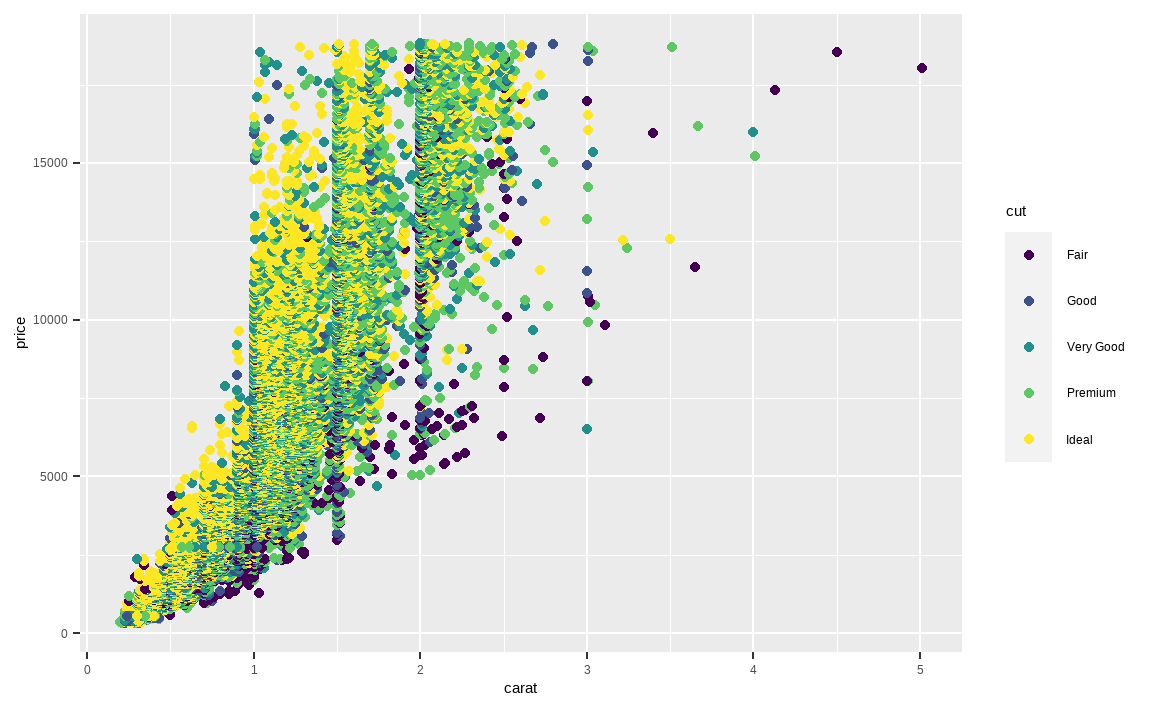
diamonds 데이터를 파이프 오퍼레이터(%>%)로 이을 경우 그대로 시각화가 가능하며, ggplot() 함수 내에 데이터를 입력하지 않아도 됩니다.
geom_point() 내부에서 aes()를 통해 점의 색깔을 매핑해줄 수 있습니다. color = cut을 지정하여 cut에 따라 점의 색깔이 다르게 표현하였습니다. 이 외에도 shape, size를 통해 모양과 크기를 각각 다르게 표현할 수 있습니다.
8.2.3 Facets
Facets은 여러 집합을 하나의 그림에 표현하기 보다 하위 집합으로 나누어 시각화하는 요소입니다.
diamonds %>%
ggplot(aes(x = carat, y = price)) +
geom_point() +
facet_grid(. ~ cut)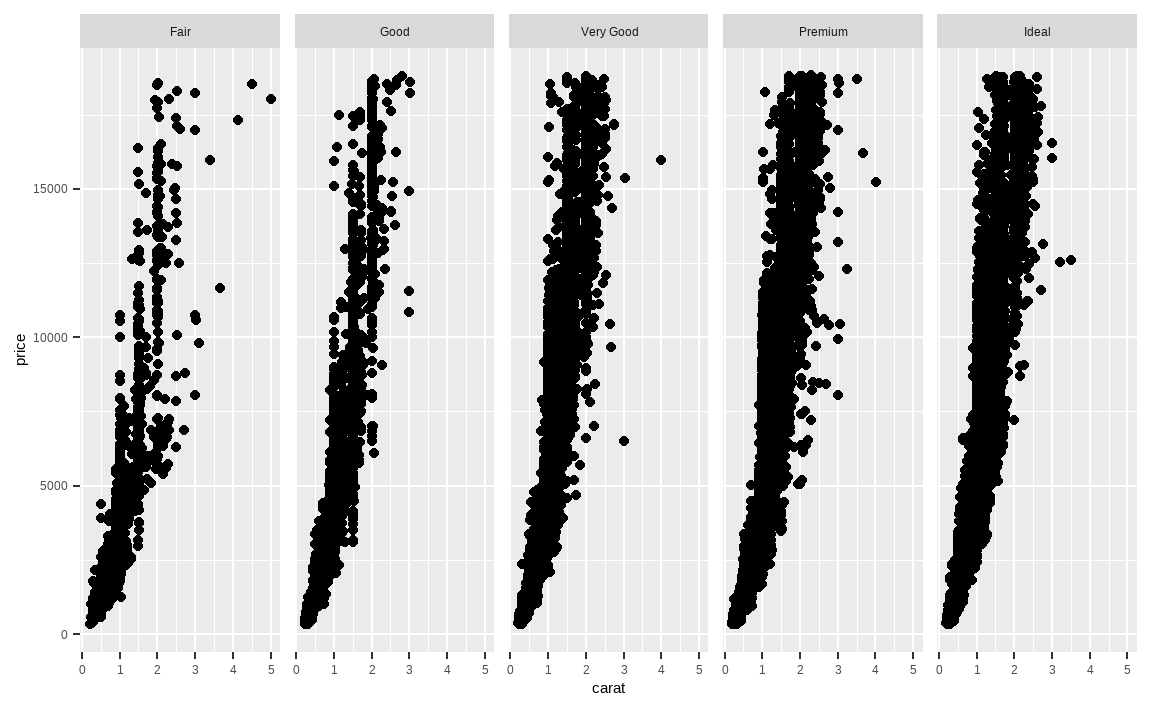
facet_grid() 혹은 facet_wrap() 함수를 통해 그림을 분할할 수 있습니다. 물결 표시(~)를 통해 하위 집합으로 나누고자 하는 변수를 선택할 수 있으며, 위 예제에서는 cut에 따라 각기 다른 그림으로 표현되었습니다.
8.2.4 Statistics
Statistics는 통계값을 나타내는 요소입니다.
diamonds %>%
ggplot(aes(x = cut, y = carat)) +
stat_summary_bin(fun.y = 'mean', geom = 'bar') 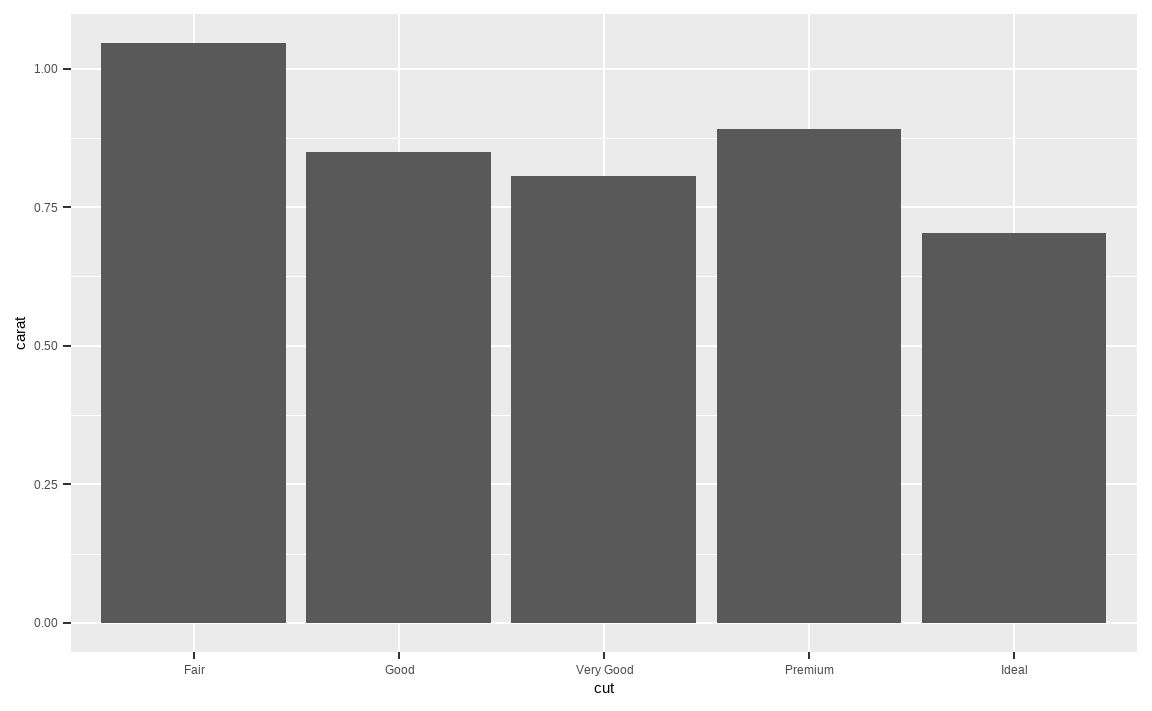
stat_summary_*() 함수를 사용하여 통계값을 표현하였습니다. cut에 따른 carat의 평균값을 구하고자 할 경우, fun.y 인자에 mean을 입력하여 평균값을 구하고, geom 인자에 bar를 입력하여 막대그래프 형태로 표현하였습니다.
8.2.5 Coordinates
Coordinates는 좌표를 의미합니다. ggplot2에서는 coord_*() 함수를 이용하여 x축 혹은 y축 정보를 변형할 수 있습니다.
diamonds %>%
ggplot(aes(x = carat, y = price)) +
geom_point(aes(color = cut)) +
coord_cartesian(xlim = c(0, 3), ylim = c(0, 20000))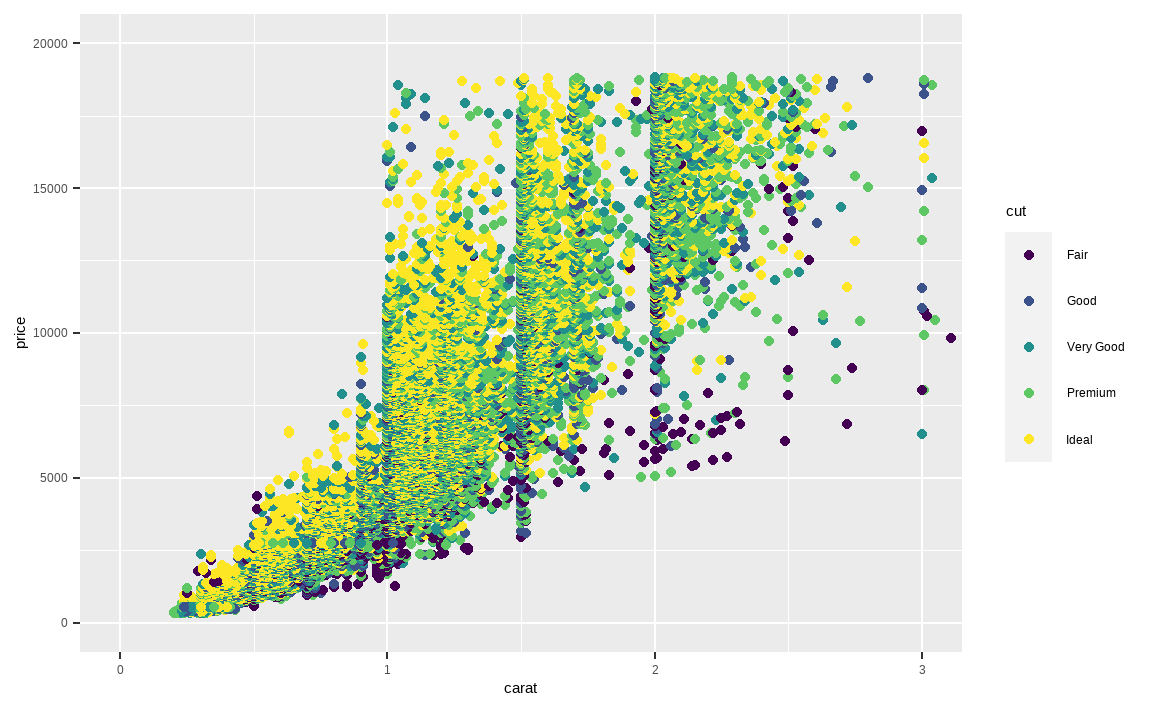
coord_cartesian() 함수를 통해 x축과 y축 범위를 지정해 줄 수 있습니다. xlim과 ylim 내부에 범위의 최소 및 최댓값을 지정해주면, 해당 범위의 데이터만을 보여줍니다.
diamonds %>%
ggplot(aes(x = carat, y = price)) +
geom_boxplot(aes(group = cut)) +
coord_flip()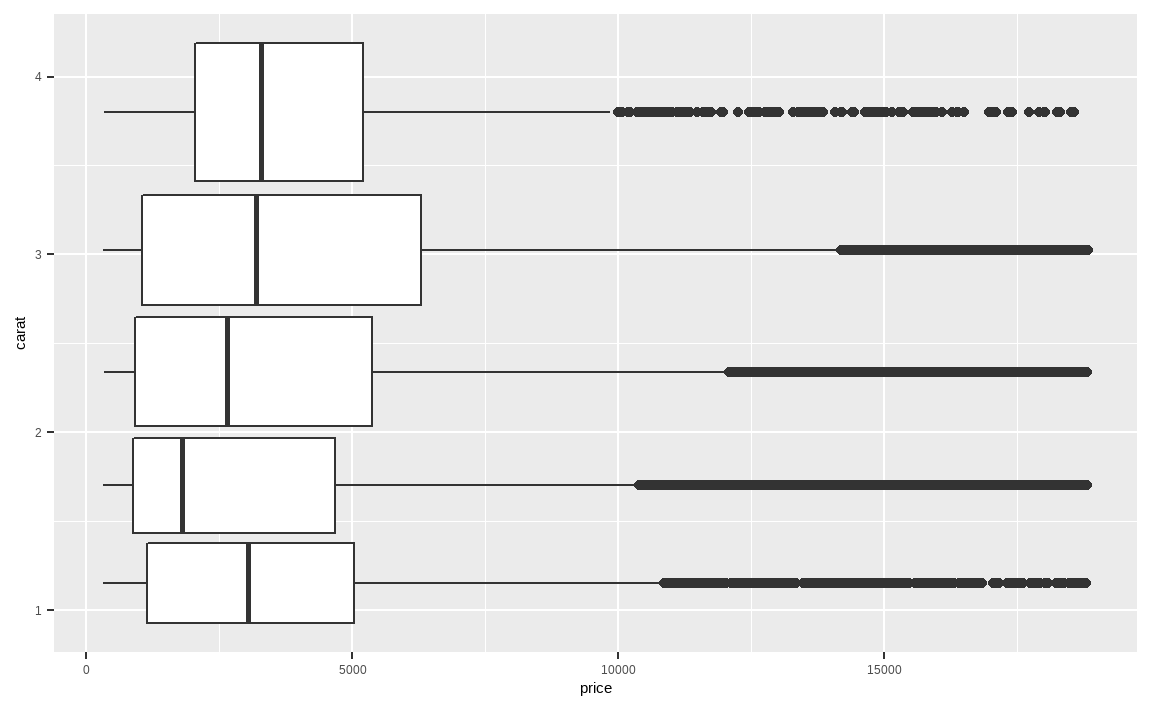
coord_flip() 함수는 x축과 y축을 뒤집어 표현합니다. ggplot() 함수의 aes 내부에서 x축은 carat을, y축은 price를 지정해 주었지만, coord_flip() 함수를 통해 x축과 y축이 서로 바뀌었습니다.
8.2.6 Theme
Theme은 그림의 제목, 축 제목, 축 단위, 범례, 디자인 등 그림을 꾸며주는 역할을 담당합니다.
diamonds %>%
ggplot(aes(x = carat, y = price)) +
geom_point(aes(color = cut)) +
theme_bw() +
labs(title = 'Relation between Carat & Price',
x = 'Carat', y = 'Price') +
theme(legend.position = 'bottom',
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.minor.y = element_blank()
) +
scale_y_continuous(
labels = function(x) {
paste0('$',
format(x, big.mark = ','))
})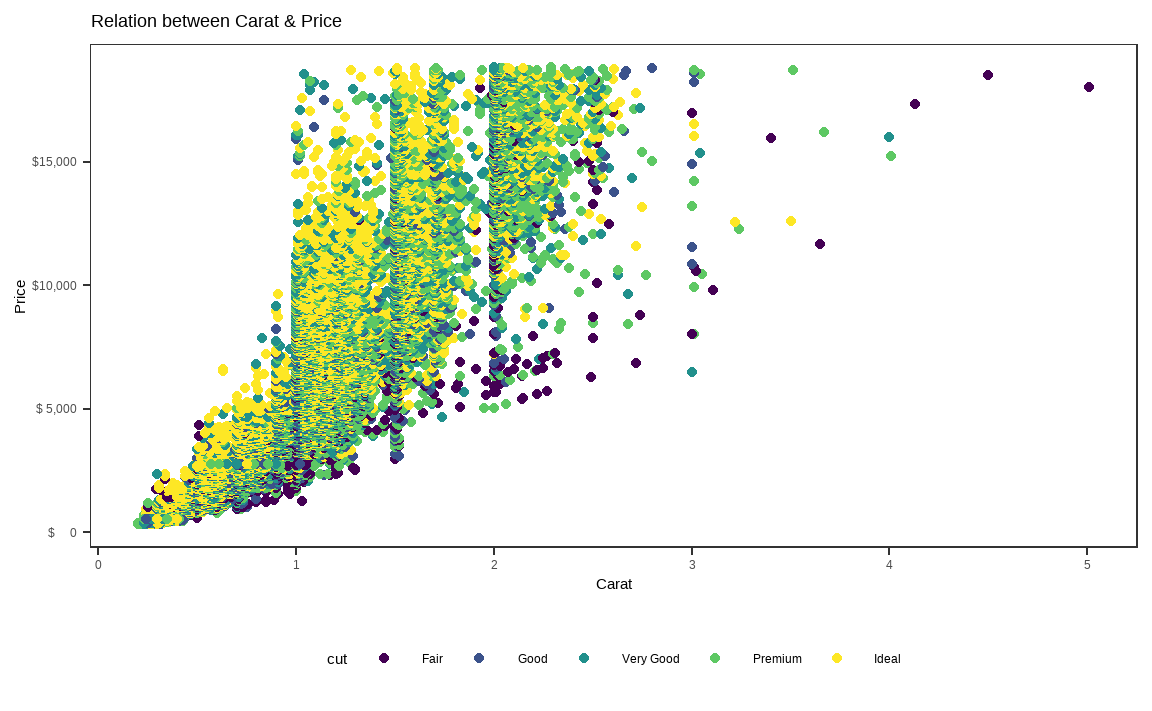
geom_point() 함수 이후 Theme에 해당하는 부분은 다음과 같습니다.
theme_bw()함수를 통해 배경을 흰색으로 설정합니다.labs()함수를 통해 그래프의 제목 및 x축, y축 제목을 변경합니다.theme()함수 내 legend.position을 통해 범례를 하단으로 이동합니다.theme()함수 내 panel.grid를 통해 격자를 제거합니다.scale_y_continuous()함수를 통해 y축에서 천원 단위로 콤마(,)를 붙여주며, 이를 달러($) 표시와 합쳐줍니다.
8.3 종목정보 시각화
이번에는 앞서 배운 내용을 바탕으로 종목정보를 시각화하도록 하겠습니다.
8.3.1 geom_point(): 산점도 나타내기
library(ggplot2)
ggplot(data_market, aes(x = ROE, y = PBR)) +
geom_point()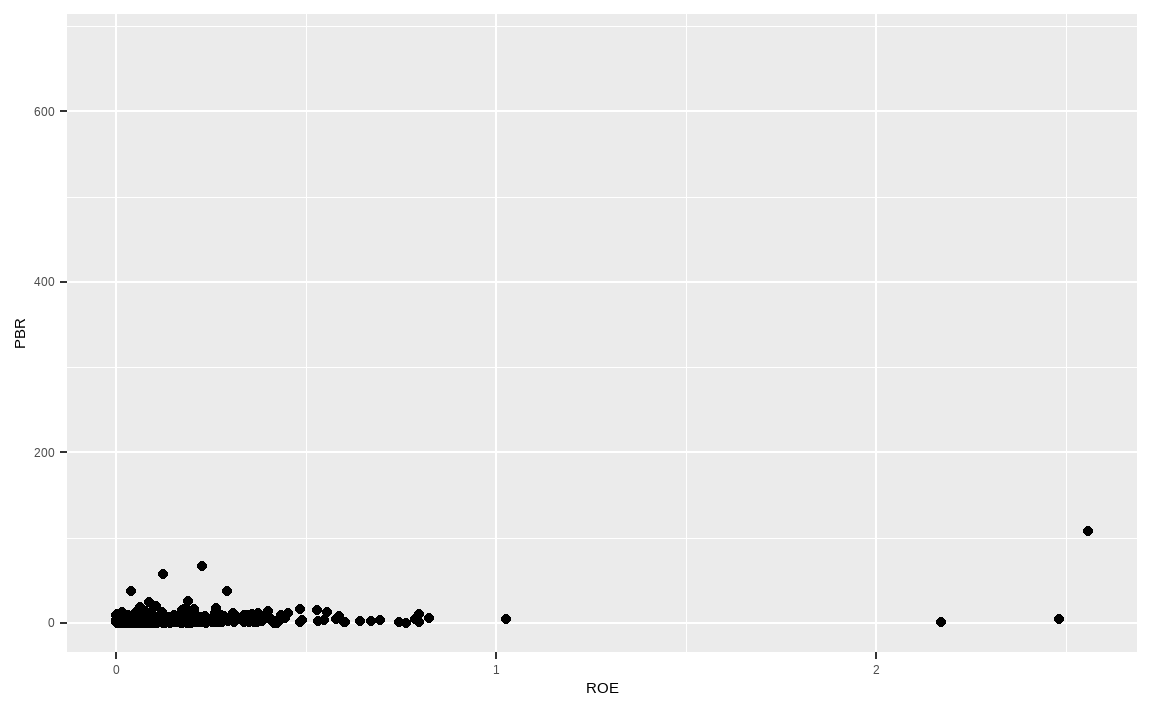
ggplot()함수 내에 사용될 데이터인 data_market을 입력합니다. aes 인자 내부에 x축은 ROE 열을 사용하고, y축은 PBR 열을 사용하도록 정의합니다.geom_point()함수를 통해 산점도 그래프를 그려줍니다. 원하는 그림이 그려지기는 했으나, ROE와 PBR에 극단치 데이터가 있어 둘 사이에 관계가 잘 보이지 않습니다.
ggplot(data_market, aes(x = ROE, y = PBR)) +
geom_point() +
coord_cartesian(xlim = c(0, 0.30), ylim = c(0, 3))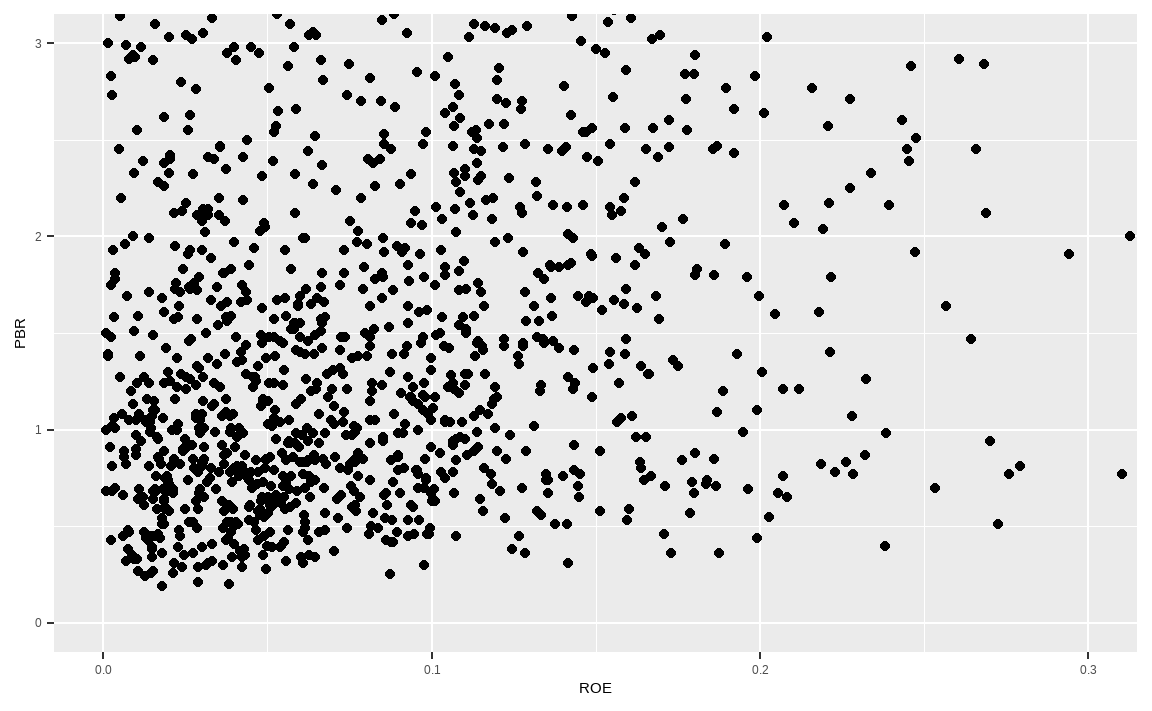
이번에는 극단치 효과를 제거하기 위해 coord_cartesian() 함수 내에 xlim과 ylim, 즉 x축과 y축의 범위를 직접 지정해줍니다. 극단치가 제거되어 데이터를 한눈에 확인할 수 있습니다.
ggplot(data_market, aes(x = ROE, y = PBR,
color = `시장구분`,
shape = `시장구분`)) +
geom_point() +
geom_smooth(method = 'lm') +
coord_cartesian(xlim = c(0, 0.30), ylim = c(0, 3))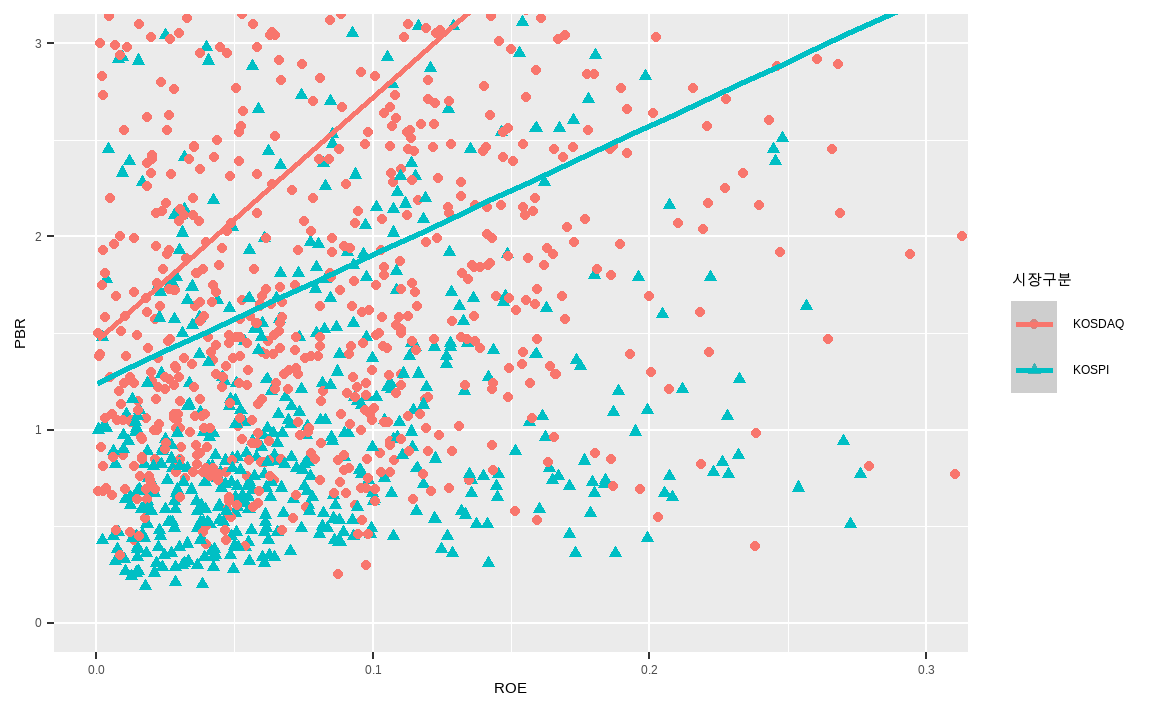
ggplot()함수 내부 aes 인자에 color와 shape를 지정해주면, 해당 그룹별로 모양과 색이 나타납니다. 코스피와 코스닥 종목들에 해당하는 데이터의 색과 점 모양을 다르게 표시할 수 있습니다.geom_smooth()함수를 통해 평활선을 추가할 수도 있으며, 방법으로 lm(linear model)을 지정할 경우 선형회귀선을 그려주게 됩니다. 이 외에도 glm, gam, loess 등의 다양한 회귀선을 그려줄 수 있습니다.
8.3.2 geom_histogram(): 히스토그램 나타내기
ggplot(data_market, aes(x = PBR)) +
geom_histogram(binwidth = 0.1) +
coord_cartesian(xlim = c(0, 10))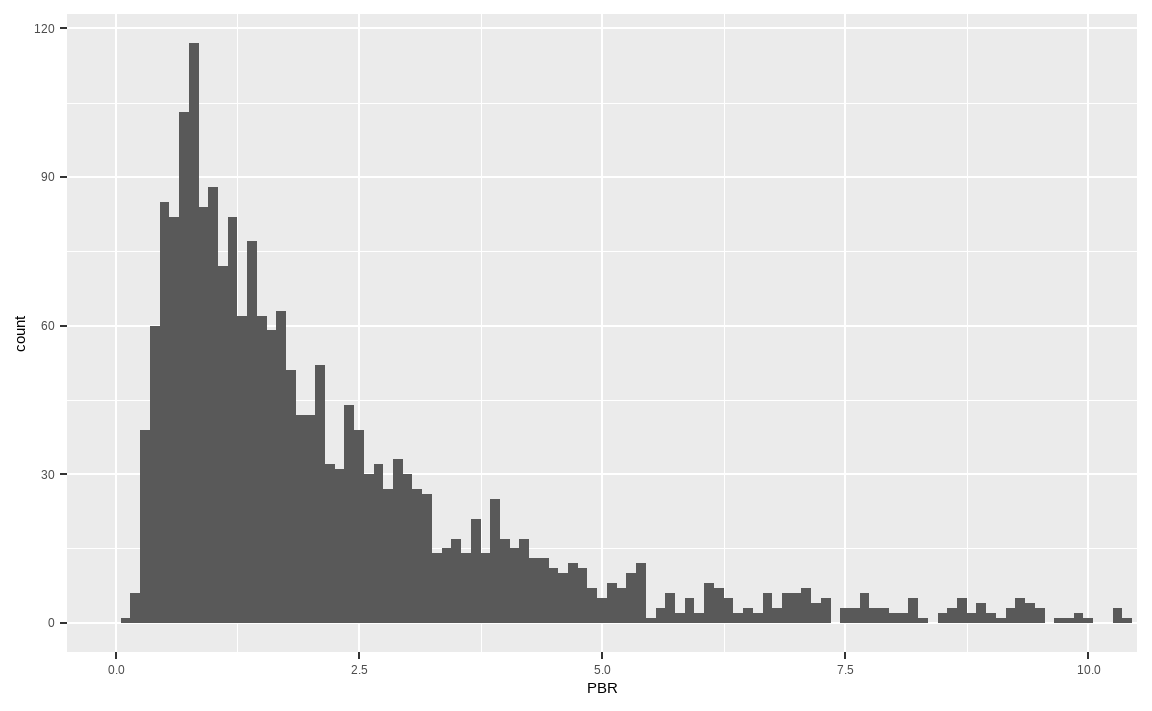
geom_histogram() 함수는 히스토그램을 나타내주며, binwidth 인자를 통해 막대의 너비를 선택해줄 수 있습니다. 국내 종목들의 PBR 데이터는 왼쪽에 쏠려 있고 오른쪽으로 꼬리가 긴 분포를 가지고 있습니다.
ggplot(data_market, aes(x = PBR)) +
geom_histogram(aes(y = ..density..),
binwidth = 0.1,
color = 'sky blue', fill = 'sky blue') +
coord_cartesian(xlim = c(0, 10)) +
geom_density(color = 'red') +
geom_vline(aes(xintercept = median(PBR, na.rm = TRUE)),
color = 'blue') +
geom_text(aes(label = median(PBR, na.rm = TRUE),
x = median(PBR, na.rm = TRUE), y = 0.05),
col = 'black', size = 6, hjust = -0.5)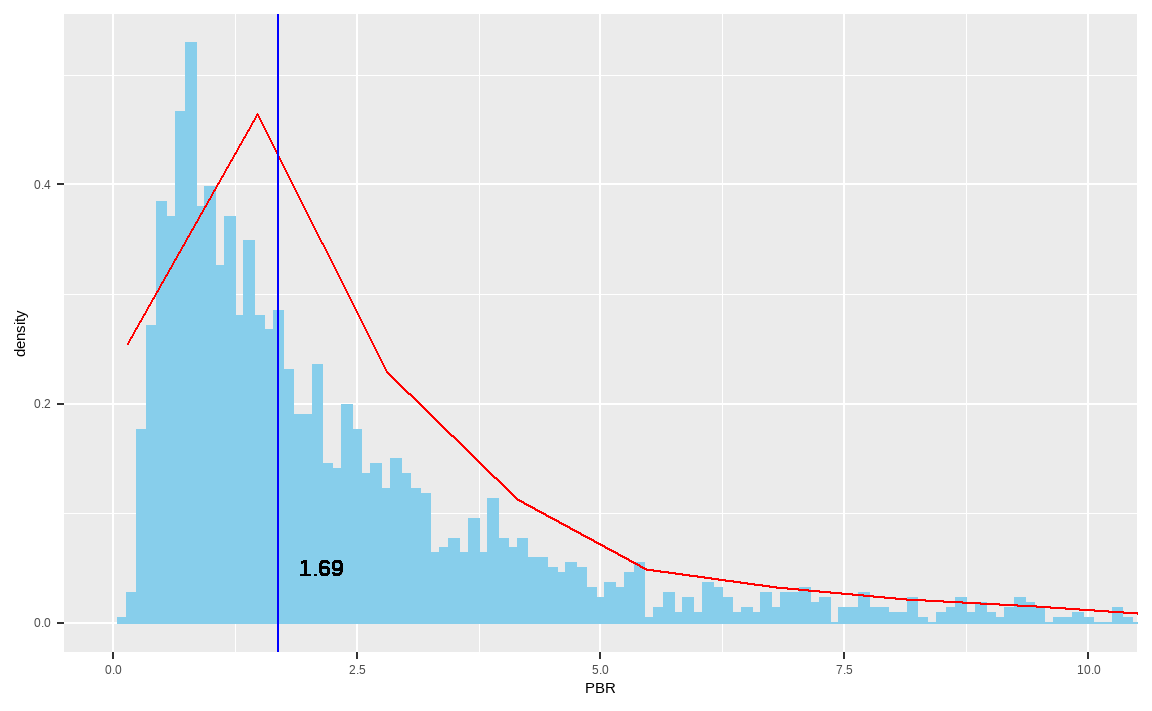
PBR 히스토그램을 좀 더 자세하게 나타내보겠습니다.
geom_histogram()함수 내에 aes(y = ..density..)를 추가해 밀도함수로 바꿉니다.geom_density()함수를 추가해 밀도곡선을 그려줍니다.geom_vline()함수는 세로선을 그려주며, xintercept 즉 x축으로 PBR의 중앙값을 선택합니다.geom_text()함수는 그림 내에 글자를 표현해주며, label 인자에 원하는 글자를 입력해준 후 글자가 표현될 x축, y축, 색상, 사이즈 등을 선택할 수 있습니다.
8.3.3 geom_boxplot(): 박스 플롯 나타내기
ggplot(data_market, aes(x = SEC_NM_KOR, y = PBR)) +
geom_boxplot() +
coord_flip()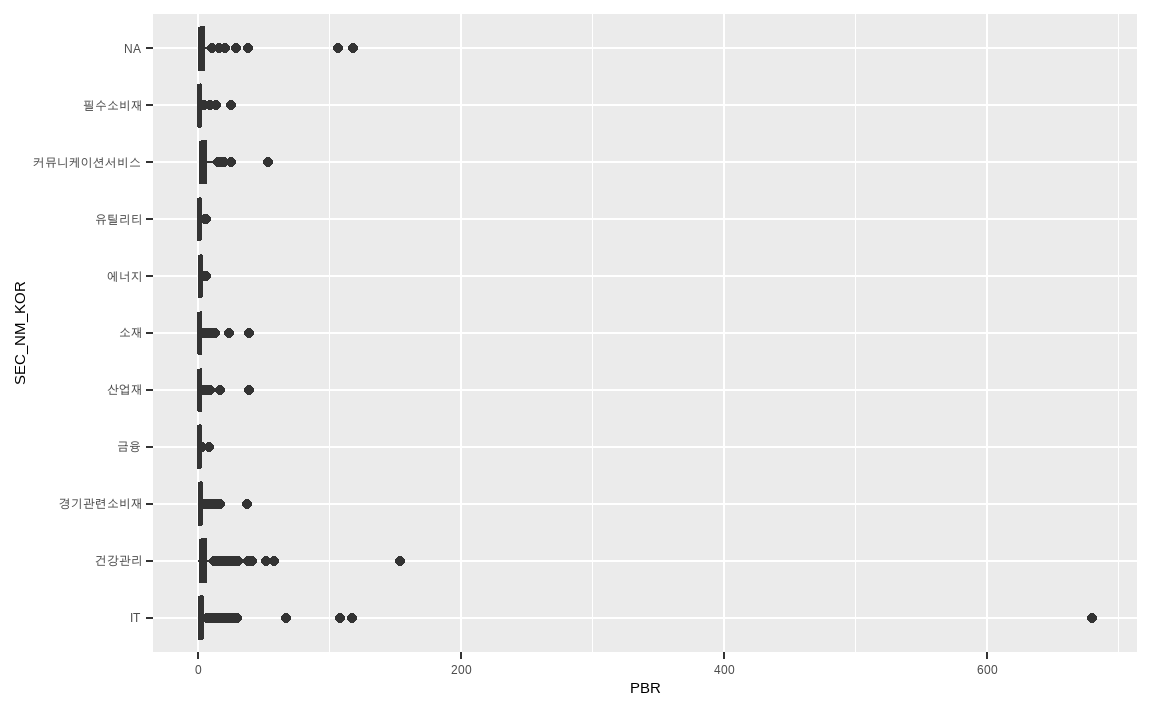
박스 플롯 역시 데이터의 분포와 이상치를 확인하기 좋은 그림이며, geom_boxplot() 함수를 통해 나타낼 수 있습니다.
- x축 데이터로는 섹터 정보, y축 데이터로는 PBR을 선택합니다.
geom_boxplot()을 통해 박스 플롯을 그려줍니다.coord_flip()함수는 x축과 y축을 뒤집어 표현해주며 x축에 PBR, y축에 섹터 정보가 나타나게 됩니다.
결과를 살펴보면 유틸리티나 금융 섹터는 PBR이 잘 모여 있는 반면, IT나 건강관리 섹터 등은 매우 극단적인 PBR을 가지고 있는 종목이 있습니다.
8.3.4 dplyr과 ggplot을 연결하여 사용하기
data_market %>%
filter(!is.na(SEC_NM_KOR)) %>%
group_by(SEC_NM_KOR) %>%
summarize(ROE_sector = median(ROE, na.rm = TRUE),
PBR_sector = median(PBR, na.rm = TRUE)) %>%
ggplot(aes(x = ROE_sector, y = PBR_sector,
color = SEC_NM_KOR, label = SEC_NM_KOR)) +
geom_point() +
geom_text(color = 'black', size = 3, vjust = 1.3) +
theme(legend.position = 'bottom',
legend.title = element_blank())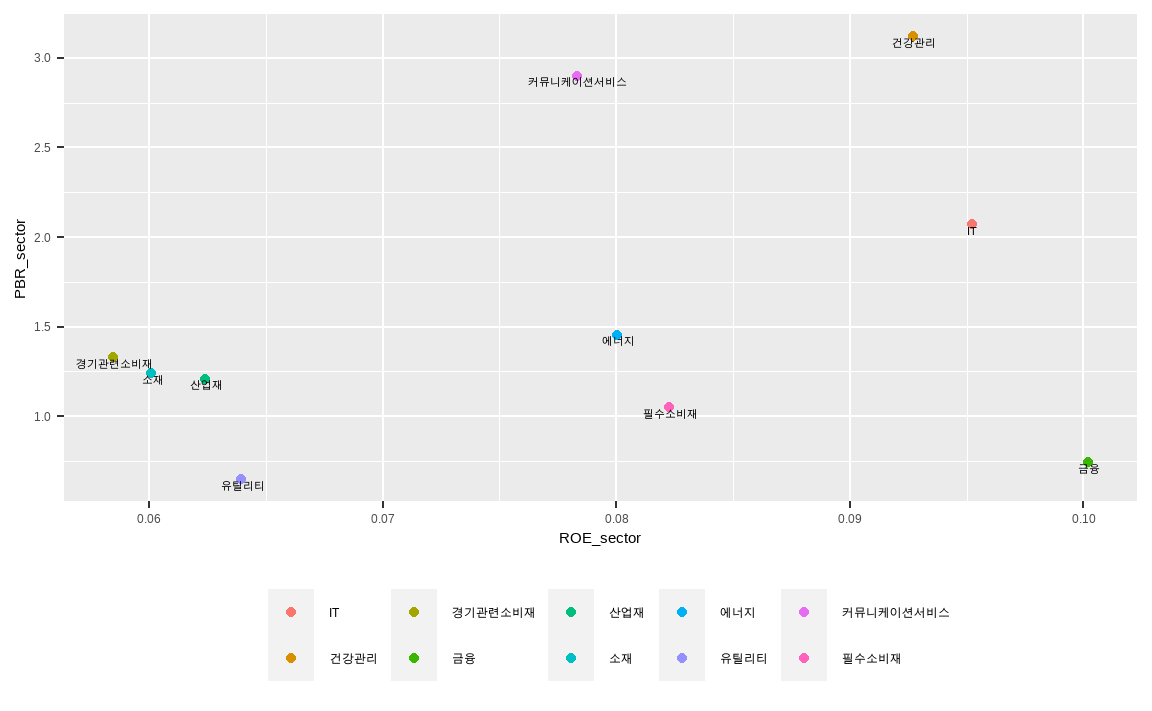
앞에서 배운 데이터 분석과 시각화를 동시에 연결해 사용할 수도 있습니다.
- 데이터 분석의 단계로
filter()를 통해 섹터가 NA가 아닌 종목을 선택합니다. group_by()를 통해 섹터별 그룹을 묶습니다.summarize()를 통해 ROE와 PBR의 중앙값을 계산해줍니다. 해당 과정을 거치면 다음의 결과가 계산됩니다.
## # A tibble: 10 x 3
## SEC_NM_KOR ROE_sector PBR_sector
## <chr> <dbl> <dbl>
## 1 IT 0.0952 2.07
## 2 건강관리 0.0927 3.12
## 3 경기관련소비재 0.0584 1.33
## 4 금융 0.100 0.745
## 5 산업재 0.0624 1.21
## 6 소재 0.0601 1.24
## 7 에너지 0.0801 1.46
## 8 유틸리티 0.0640 0.65
## 9 커뮤니케이션서비스 0.0783 2.9
## 10 필수소비재 0.0822 1.05해당 결과를 파이프 오퍼레이터(%>%)를 이용하여 ggplot() 함수와 연결해줍니다.
- x축과 y축을 설정한 후 색상과 라벨을 섹터로 지정해주면 각 섹터별로 색상이 다른 산점도가 그려집니다.
geom_text()함수를 통해 앞에서 라벨로 지정한 섹터 정보들을 출력해줍니다.theme()함수를 통해 다양한 테마를 지정합니다. legend.position 인자로 범례를 하단에 배치했으며, legend.title 인자로 범례의 제목을 삭제했습니다.
8.3.5 geom_bar(): 막대 그래프 나타내기
data_market %>%
group_by(SEC_NM_KOR) %>%
summarize(n = n()) %>%
ggplot(aes(x = SEC_NM_KOR, y = n)) +
geom_bar(stat = 'identity') +
theme_classic()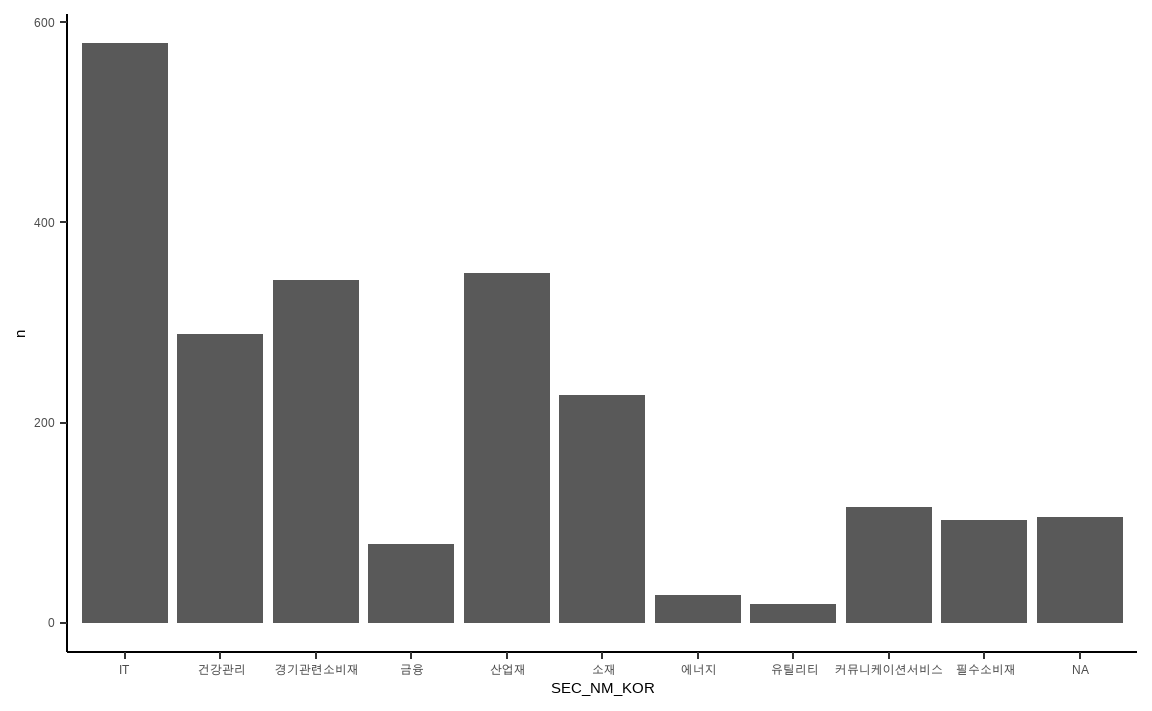
geom_bar()는 막대 그래프를 그려주는 함수입니다.
group_by()를 통해 섹터별 그룹을 묶어줍니다.summarize()함수 내부에n()을 통해 각 그룹별 데이터 개수를 구합니다.ggplot()함수에서 x축에는 SEC_NM_KOR, y축에는 n을 지정해줍니다.geom_bar()를 통해 막대 그래프를 그려줍니다. y축에 해당하는 n 데이터를 그대로 사용하기 위해서는 stat 인자를 identity로 지정해주어야 합니다.theme_*()함수를 통해 배경 테마를 바꿀 수도 있습니다.
한편 위 그래프는 데이터 개수에 따라 순서대로 막대가 정렬되지 않아 보기에 좋은 형태는 아닙니다. 이를 반영해 더욱 보기 좋은 그래프로 나타내보겠습니다.
data_market %>%
filter(!is.na(SEC_NM_KOR)) %>%
group_by(SEC_NM_KOR) %>%
summarize(n = n()) %>%
ggplot(aes(x = reorder(SEC_NM_KOR, n), y = n, label = n)) +
geom_bar(stat = 'identity') +
geom_text(color = 'black', size = 4, hjust = -0.3) +
xlab(NULL) +
ylab(NULL) +
coord_flip() +
scale_y_continuous(expand = c(0, 0, 0.1, 0)) +
theme_classic()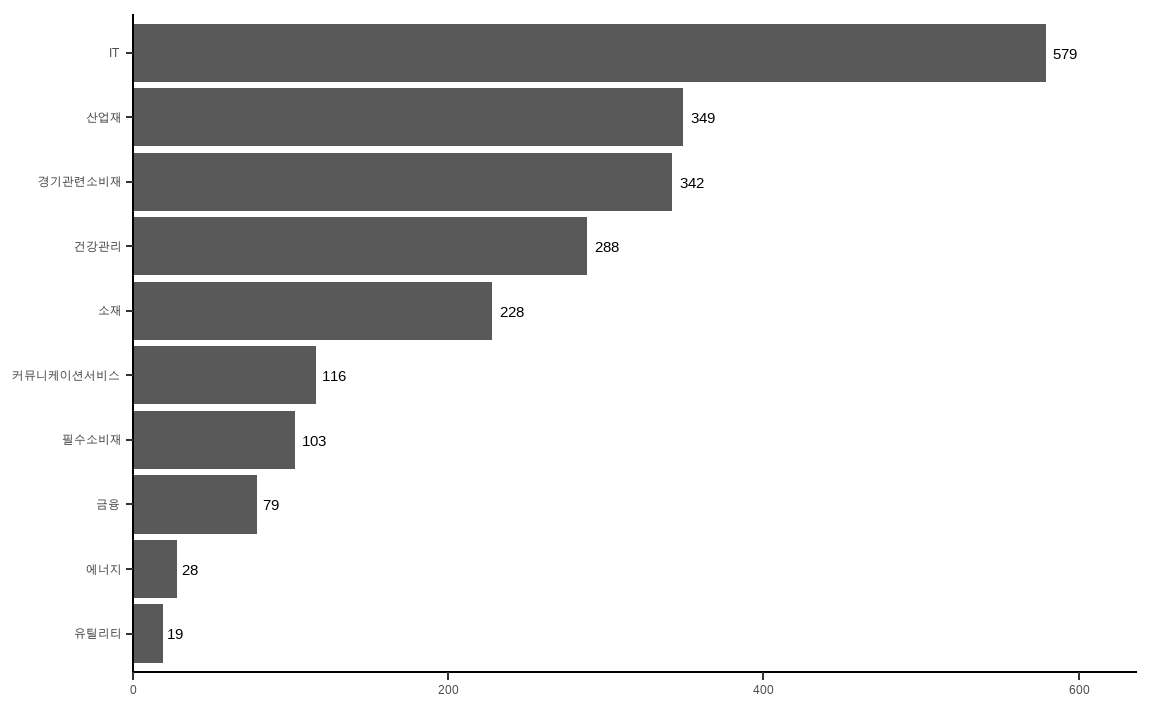
filter()함수를 통해 NA 종목은 삭제해준 후 섹터별 종목 개수를 구해줍니다.ggplot()의 x축에reorder()함수를 적용해 SEC_NM_KOR 변수를 n 순서대로 정렬해줍니다.geom_bar()를 통해 막대 그래프를 그려준 후geom_text()를 통해 라벨에 해당하는 종목 개수를 출력합니다.xlab()과ylab()에 NULL을 입력해 라벨을 삭제합니다.coord_flip()함수를 통해 x축과 y축을 뒤집어줍니다.scale_y_continuous()함수를 통해 그림의 간격을 약간 넓혀줍니다.theme_classic()으로 테마를 변경해줍니다.
결과를 보면 종목수가 많은 섹터부터 순서대로 정렬되어 보기도 쉬우며, 종목수도 텍스트로 표현되어 한눈에 확인할 수 있습니다.
이처럼 데이터 시각화를 통해 정보의 분포나 특성을 한눈에 확인할 수 있으며, ggplot()을 이용하면 복잡한 형태의 그림도 매우 간단하고 아름답게 표현할 수 있습니다.
8.4 주가 및 수익률 시각화
주가 혹은 수익률을 그리는 것 역시 매우 중요합니다. R의 기본 함수로도 주가나 수익률을 나타낼 수 있지만, 패키지를 사용하면 더욱 보기 좋은 그래프를 그릴 수 있습니다. 또한 최근에 나온 여러 패키지들을 이용하면 매우 손쉽게 인터랙티브 그래프를 구현할 수도 있습니다.
8.4.1 주가 그래프 나타내기
library(quantmod)
getSymbols('SPY')
prices = Cl(SPY)getSymbols() 함수를 이용해 미국 S&P 500 지수를 추종하는 ETF인 SPY의 데이터를 다운로드한 후 Cl() 함수를 이용해 종가에 해당하는 데이터만 추출합니다. 이제 해당 가격 및 수익률을 바탕으로 그래프를 그려보겠습니다.
plot(prices, main = 'Price')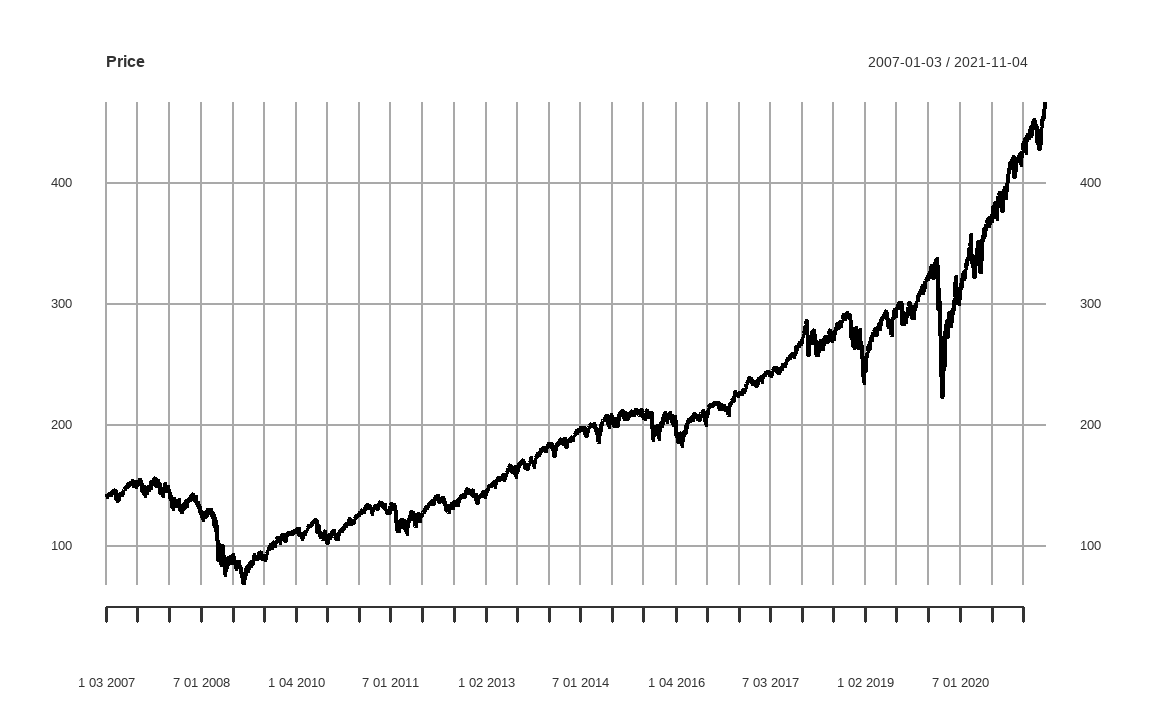
getSymbols() 함수는 데이터를 xts 형식으로 다운로드합니다. R에서는 데이터가 xts 형식일 경우 기본 함수인 plot()으로 그래프를 그려도 x축에 시간을 나타내고 오른쪽 상단에 기간을 표시합니다. 그러나 완벽히 깔끔한 형태의 그래프라고 보기에 어려운 면이 있습니다.
library(ggplot2)
SPY %>%
ggplot(aes(x = Index, y = SPY.Close)) +
geom_line()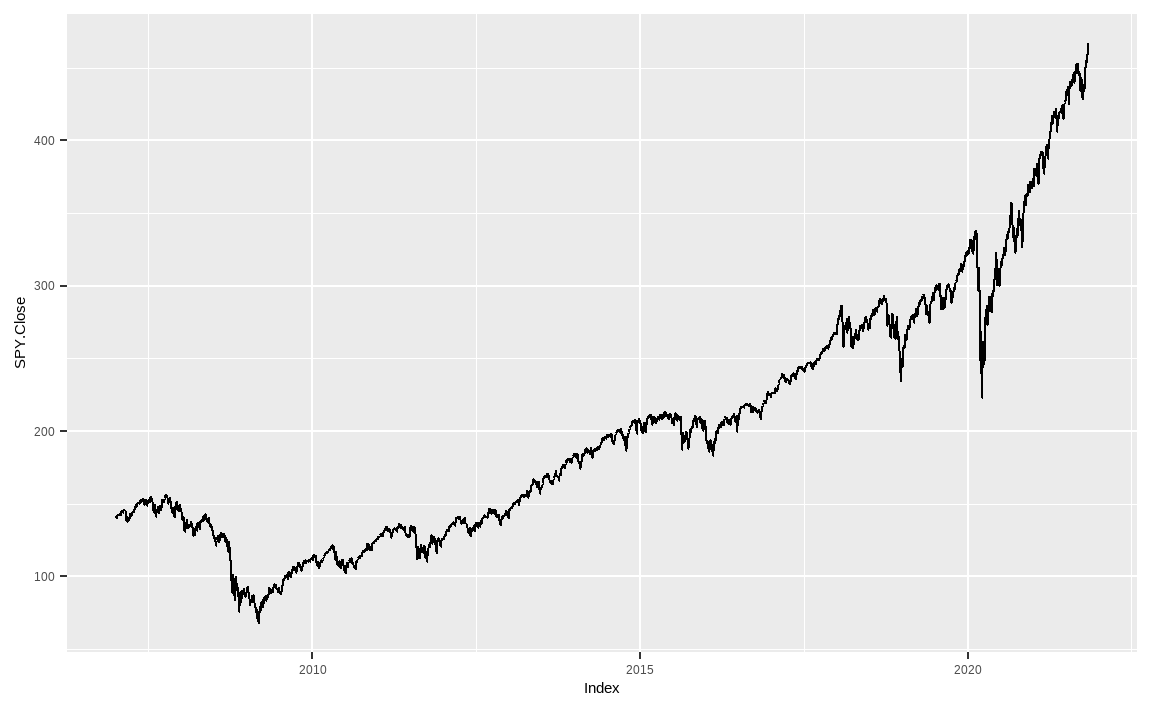
ggplot()을 이용하면 기본 plot()보다 한결 깔끔해지며, 패키지 내의 다양한 함수를 이용해 그래프를 꾸밀 수도 있습니다.
8.4.2 인터랙티브 그래프 나타내기
library(dygraphs)
dygraph(prices) %>%
dyRangeSelector()dygraphs 패키지의 dygraph() 함수를 이용하면 사용자의 움직임에 따라 반응하는 그래프를 그릴 수 있습니다. 해당 패키지는 JavaScript를 이용해 인터랙티브한 그래프를 구현합니다. 그래프 위에 마우스 커서를 올리면 날짜 및 가격이 표시되기도 하며, 하단의 셀렉터를 이용해 원하는 기간의 수익률을 선택할 수도 있습니다.
library(highcharter)
highchart(type = 'stock') %>%
hc_add_series(prices) %>%
hc_scrollbar(enabled = FALSE)highcharter 패키지의 highchart() 함수 역시 이와 비슷하게 인터랙티브 그래프를 생성해줍니다. 왼쪽 상단의 기간을 클릭하면 해당 기간의 수익률만 확인할 수 있으며, 오른쪽 상단에 기간을 직접 입력할 수도 있습니다.
library(plotly)
p = SPY %>%
ggplot(aes(x = Index, y = SPY.Close)) +
geom_line()
ggplotly(p)plotly 패키지는 R뿐만 아니라 Python, MATLAB, Julia 등 여러 프로그래밍 언어에 사용될 수 있는 그래픽 패키지로서 최근에 많은 사랑을 받고 있습니다. R에서는 단순히 ggplot()을 이용해 나타낸 그림에 ggplotly() 함수를 추가하는 것만으로 인터랙티브한 그래프를 만들어줍니다.
또한 해당 패키지는 최근 샤이니에서도 많이 사용되고 있습니다. 따라서 샤이니를 이용한 웹페이지 제작을 생각하고 있는 분이라면, 원래의 함수 실행 방법도 알아두는 것이 좋습니다.
prices %>%
fortify.zoo %>%
plot_ly(x= ~Index, y = ~SPY.Close ) %>%
add_lines()plot_ly() 함수 내부에 x축과 y축을 설정해주며, 변수명 앞에 물결표(~)를 붙여줍니다. 그 후 add_lines() 함수를 추가하면 선 그래프를 표시해줍니다. ggplot() 함수는 플러스 기호(+)를 통해 각 레이어를 연결해주었지만, plot_ly() 함수는 파이프 오퍼레이터(%>%)를 통해 연결할 수 있다는 장점이 있습니다.
8.4.3 연도별 수익률 나타내기
주가 그래프 외에 연도별 수익률을 그리는 것도 중요합니다. ggplot()을 통해 연도별 수익률을 막대 그래프로 나타내는 방법을 살펴보겠습니다.
library(PerformanceAnalytics)
ret_yearly = prices %>%
Return.calculate() %>%
apply.yearly(., Return.cumulative) %>%
round(4) %>%
fortify.zoo() %>%
mutate(Index = as.numeric(substring(Index, 1, 4)))
ggplot(ret_yearly, aes(x = Index, y = SPY.Close)) +
geom_bar(stat = 'identity') +
scale_x_continuous(breaks = ret_yearly$Index,
expand = c(0.01, 0.01)) +
geom_text(aes(label = paste(round(SPY.Close * 100, 2), "%"),
vjust = ifelse(SPY.Close >= 0, -0.5, 1.5)),
position = position_dodge(width = 1),
size = 3) +
xlab(NULL) + ylab(NULL)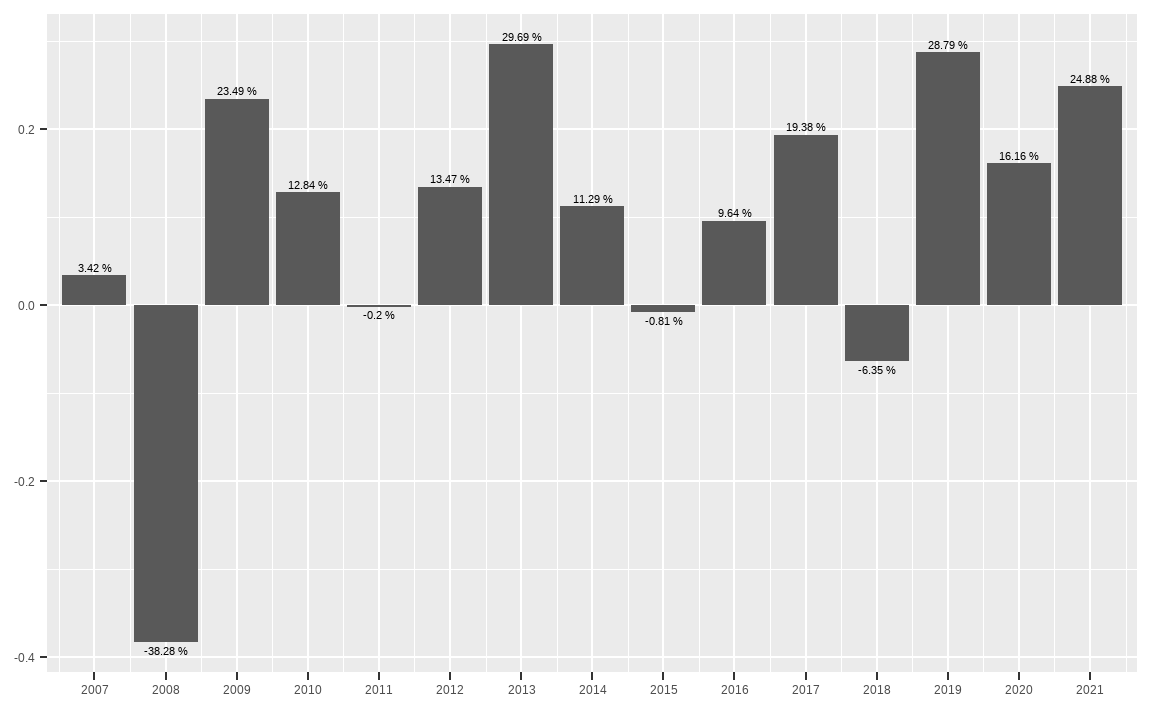
apply.yearly()함수를 이용해 연도별 수익률을 계산한 뒤 반올림합니다.fortify.zoo()함수를 통해 인덱스에 있는 시간 데이터를 Index 열로 이동합니다.mutate()함수 내에substring()함수를 통해 Index의 1번째부터 4번째 글자, 즉 연도에 해당하는 부분을 뽑아낸 후 숫자 형태로 저장합니다.ggplot()함수를 이용해 x축에는 연도가 저장된 Index, y축에는 수익률이 저장된 SPY.Close를 입력합니다.geom_bar()함수를 통해 막대 그래프를 그려줍니다.scale_x_continuous()함수를 통해 x축에 모든 연도가 출력되도록 합니다.geom_text()를 통해 막대 그래프에 연도별 수익률이 표시되도록 합니다.vjust()내에ifelse()함수를 사용해 수익률이 0보다 크면 위쪽에 표시하고, 0보다 작으면 아래쪽에 표시되도록 합니다.
해당 과정을 거치면 막대 그래프와 텍스트를 통해 연도별 수익률을 한눈에 확인할 수 있게 됩니다.